


2017 年 4 月 3 日(北京时间 4 月 4 日)Google 和 Adobe 联合发布了他们共同合作的第二款完全免费开源的「泛中日韩字体」,成为设计界、技术界的一大新闻。这套字由七款字重构成,内含字形达到了 OpenType 规格上限的 65 535 个。由于整个项目的内容非常庞大而复杂,涉及商业合作、开源版权、字体设计、文字编码、工程技术等多方面的内容,大家在好奇的同时不免也会产生了不少疑问。针对中文媒体上存在一些不甚准确的说法,我们在此用问答的形式对这套字加以说明,供大家在使用、开发时参考。
这套字体到底叫什么名字?
与 2014 年发布的第一个项目一样,这个项目的成果也是「一套字体两个名字」,两家公司分别按照自己的品牌进行包装:Google 方面把它作为 Google Noto Fonts 项目里 Noto CJK 的一部分,将这次发布的字体命名为 Noto Serif CJK;而 Adobe 方面将其作为该公司字体开源项目 Source 系列里 Source Han 的的一部分,将这次发布的字体命名为 Source Han Serif。
Google 的 Noto 系列名称,来自其「消灭豆腐块」(no more tofu, □) 让字符都能正常显示的愿景。此项目已经覆盖了全球众多文种,其中绝大部分是 Google 与 Monotype 公司合作的,而与 Adobe 合作的东亚部分明显是引用了 Unicode 中「中日韩统一表意文字」的术语(虽然实际上是 CJKV「中日韩越」),在名字里加了 CJK 这三个字母。
出于其完全开源、免费的性质,Adobe 将这个系列命名为 Source,所以单纯说 Source Serif,指的是 Adobe 另外一套开源的西文衬线字体;而只有说 Source Han Serif,才是指这款泛中日韩字体——很显然中间的 Han 不能随便省略,否则会指代不明。
与 Google 不同,Adobe 还为各个区域分别起了本地化的名字:中文名字从 Source「源」的含义而来,无论繁简都称作「思源宋体」(注意不是「明体」),这和「思源黑体」一样,命名也有「饮水思源」的用意;在日文则称作「源ノ明朝」(げんのみんちょう、Gen-no-minchō),既避免了音译之后与「甜酱 (sauce)」相混,「源」字不训读成「みなもと」(minamoto) 而用音读的「げん」(gen) 也顺利解决了商标注册申请问题,中间加上片假名「ノ」还可以向吉卜力动画片致敬;而韩文名称「본명조」(Bon-myeong-jo) 按照韩文汉字写出来其实就是「本明朝」,即「根本」的「本」。
请注意,「衬线」「无衬线体」(Serif/Sans Serif) 原本是西文字体里的概念,我们只是其风格对应到中文的「宋体/黑体」,日文的「明朝体」「ゴシック体」也是这样。尽管字体风格上类似,但从字体设计的严格定义上来说「西文衬线体=中文宋体=日文明朝体」是不太恰当的。
为行文方便,如果没有特别指出,下文通称「思源宋体」。
Google 版和 Adobe 版有什么区别?
如上所述,Google 版的 Noto Serif CJK和 Adobe 版的思源宋体的区别只在于名字,因此实际的 OpenType 字体文件 name table 里关于版权、厂商的相关数值分别写进了两家公司的内容。另外,为了回避Android 系统上的 bug,Noto 版本中 U+2252 (≒) 和 U+25C8 (◈) 这两个码位没有映射到字形上。除去这些细节方面,二者完全没有区别。
真的没豆腐吗?这套字到底覆盖了多少字?
Google「没有豆腐块」的愿景是好的,但由于现在 Unicode 收字已浩如烟海,一套字不可能完整覆盖所有中日韩汉字。按照 Google 官方网站上的说明,这套字只是「完全覆盖了 Unicode 里『基本多文种平面』(BMP)的中日韩表意文字,并为支持中国和日本的标准,对第二平面提供了有限支持。」
我们最关心的「中日韩统一表意文字」里只有主区(20 914 字)和「扩充 A 区」(6582 字)在「基本多文种平面」里面。剩下的扩充 B、C、D、E(以及即将发布的 F)区都在第二平面上,因此都是「有限支持」。
另外,从「字形」的角度分别来看四个文种的情况:
| 文 种 | 字形数 | 支 持 标 准 |
| 简体中文 | 30 995 | 所有 GB18030 汉字和《通用规范汉字表》 |
| 繁体中文 | 16 383 | 所有大五码汉字以及七个倚天码汉字 |
| 日 文 | 17 875 | 所有 Adobe-Japan1-6 日本汉字 |
| 韩 文 | 24 752 | 所有现代(11 172 个)和常用古代(500 个)韩字音节和「可组合韩字字母」,还有全部 KS X 1001 与 1002 的(7476 个)韩文汉字以及增补的 466 个韩文汉字 |

相信大家已经看到,如果将上表四个字形数量单纯相加会超过九万,而一个 OpenType 字体文件的上限只能收到 65 535 个字形,因此思源项目需要将中日韩里一样的字形进行共享,否则无论如何都是放不下的。思源宋体的设计师针对 Unicode 的 43 029 个码位放置了六万多个字形,比如在 14 697 个码位上采用了四个区域完全相同的字形共享,而在 270 个码位(都在「基本多文种平面」里面)上放置了四个区域各不相同的字形。剩下的码位也是按情况分别判断是共享还是分开,逐一安置。另外,这套字配备了从 Extralight 到 Heavy 共七款字重,因此要配置的字形达 46 万个之多,这就是这个项目庞大而复杂的原因。
作为简体中文用户,我想知道「思源宋体」收的字和 GB 18030 以及《通用规范汉字表》到底是什么关系?
从上表可以看到,思源宋体支持简体中文的字形数量是 30 995 个。而 GB 18030–2000 字汇里收的 27 533 个汉字都在「基本多文种平面」里面,因此「思源宋体」是完全支持的。
另一方面,中国国务院 2013 年发布的《通用规范汉字表》里规定了 8105 个规范字,而这其中有 199 个规范字超出了 GB18030–2000 范围。其中有 196 个分别落在扩充 B、C、D、E 区 ,还有三个规范字(U+9FCD 鿍、U+9FCE 鿎、U+9FCF 鿏)后来在 2015 年发布的 Unicode 8.0 版本增补到了「基本多文种平面」里。由于思源字体对这些字做了特别对待的「有限支持」,因此都可以正常显示。单从字形覆盖这一点,对比中国商业字体的现状,可以说思源宋体已经走在中国字体产品前列。
「中文部分由华文制作」这种说法对吗?
思源宋体制作由 Adobe 公司的小林剑博士总负责,并由日本 Adobe 的字体团队具体操作,包括主设计师

和思源黑体一样,常州华文公司设计制作了繁体中文和简体中文字形,数量极其庞大。但是,由于思源项目中日韩的字形有复杂的共享关系,有的字形可以拿到繁简日韩四个版本共享,有的却不行。最后的成品中,简体中文里有些字形是从日文共享过来的,并不是华文制作的;反过来在日文里也有些字形是华文做的,因此严格来说不是完全的一一对等关系。
这套字的开发制作前后耗费了多长时间?
思源宋体的实际设计开发工作于 2014 年底,也就是思源黑体发布后的几个月就已经开始着手。华文在 2015 年中期开始了中文字形的制作,之后经过四个内测版和两个发布候选版 (Release Candidate),最终于 2017 年 4 月发布,实际发布时间比原先计划推迟了两三个月。
那个 biáng 到底是什么?为什么字符串里有好多虚线框框?
这次思源宋体发布新闻里,转载率最高的莫过于其中的一个彩蛋:对 biáng 字的支持。拷贝下述字符串,选择思源宋体即可显示。当然,中日韩版本的字形也不尽相同。
-
- (繁体)⿺辶⿳穴⿰月⿰⿲⿱幺長⿱言馬⿱幺長刂心
- (简体)⿺辶⿳穴⿰月⿰⿲⿱幺长⿱言马⿱幺长刂心

陕西关中地区的这道知名传统风味面食的名称据说是书写最复杂、笔画最多的汉字之一,最常见字形有 56 画,而实际上还有繁体、简体等不同版本。此字还没有进入 Unicode,但是相关提案已经提交,预计会收入中日韩统一汉字的扩充 G 区。
这个字形其实早在 2015 年就已经画好了,而 Adobe 制作这个字的原因其实很简单:首先是为了对其内部造字系统「表意文字笔形库」(Ideograph Element Library) 进行压力测试;而另外一个目的则更为实际,因为 2015 年当时小林剑博士向 Unicode 技术委员会递交这个字编码提案的报告里需要这个显示字形。
大家首先好奇的是这个序列里莫名其妙的虚线框框是什么东西。这当然不是乱码,而是 Unicode 规范里的「表意文字描述符」(Ideographic Description Character,IDC),码位在 U+2FFx 这一列上。这些描述符的原理很简单,比如「⿰木目」表示将「木」「目」两个部件左右组合,组合结果就是「相」。这套组合符一共有十二种,可以多个叠加使用。采用这种方法可以将这些尚未编码的汉字以文本代码的方式记录下来,为将来查找替换提供极大便利。
从技术上来说,思源宋体只是提前为这个还没有正式 Unicode 码位的字预先描绘好了字形,然后通过 OpenType 特性设置之后供应用软件调用而已。这并不是一个高新科技,因为这些特性早在二十年前 OpenType 发布时候就已经有了。
需要强调的是,思源宋体里采用的并不是 liga(Standard Ligatures,标准合字)特性,而是 ccmp(Glyph Composition / Decomposition,字形组合/分解)的 GSUB 特性来进行调用的。这样的考虑是因为 liga 特性要依靠用户端手动去开启关闭,而 ccmp 特性是默认打开的。具体细节可以看小林剑博士的博客文章。
无论用字体方面采用什么特性,最后还是需要客户端环境的支持。支持ccmp 特性的环境并没有 liga 特性多。比如,虽然在 macOS 系统层级就可以支持显示这个字,但在目前最新版的 Word for Mac 里却依然无法成功调用。因此,这个彩蛋能否正常显示,需要在各个系统、应用测试确认。
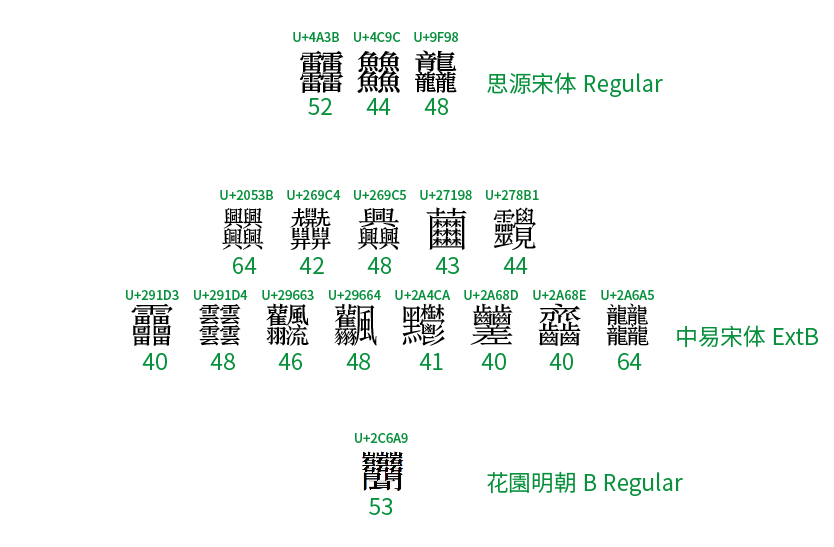
另外,这个字其实并不是笔画数最多的字。事实上,Unicode 里已经收了有很多笔画数超四十的汉字,下面是其中一部分(括号里是其笔画数):
- 思源宋体支持的扩充 A 区: 䨻 (52), 䲜 (44), 龘 (48);
- 超出思源宋体支持的扩充 B 区: ? (64), ? (42), ? (48), ? (43), ? (44), ? (40), ? (48), ? (46), ? (48), ? (41), ? (40), ? (40), ? (64)
- 超出思源宋体支持的扩充 E 区: ? (53)。
考虑到各种环境不一定能正常显示,特将上述字符用图片显示如下:
思源宋体在设计上什么特点?
由于设计本身是基于 Adobe 公司在 1998 年发布的日文字体「小塚明朝」(Kozuka Mincho) ,思源宋体的字形和「小塚明朝」一样,都是用该公司统一配备的「表意文字笔形库」分发给包括华文在内的合作厂商进行拼字设计而成的。笔形库里的笔形总数达 187 种,其中还包括针对简体中文增加的一些特殊笔形(如「撇点」)。



思源宋体与我们常见的以「宋二」为基础的老版数码字体相比,中宫更大、重心更低。但是和原版「小塚明朝」相比,思源宋体的中宫进行了约 98% 的缩小处理,而为屏幕背光显示的需要将原本较细的横画适当进行了加粗。其设计介于传统宋体和现代宋体中间,但总体来说略偏现代。



思源宋体的笔形完全符合规范么?
思源宋体简体中文的字形基本依照《通用规范汉字表》的写法。但由于 2013 年发布的《通用规范汉字表》本身没有对字形作出明确详细的解说,因此对于一些笔画的处理是到底「字形差异」还是「设计差异」并无法判断。比如对于「四」「西」等汉字里竖弯与右框是否接触的问题,似乎规范字形本身就没有统一,而思源宋体则出于设计考虑处理成「全接触」。
同样的问题也出现在繁体中文里。思源宋体繁体中文版中「口」的双脚出头、立字中的两笔上下是否接触、糸字旁下面三点朝向、言字旁上方两笔是否相触等等,都和「细明体」的处理方法不同,尽管这些细节在台湾「国字标准字体」里其实并没有明文规定。总体来说,思源宋体的处理方法属于「设计差异」范畴。


这次思源宋体发布的繁体中文采用的是台湾的字形标准,为什么没有香港版?
的确,这次发布的繁体中文是按照台湾的字形标准制作的。香港字形版已经在计划中,但是要放到第二版才会发布。主要原因是,香港特别行政区的中文界面咨询委员会工作小组正在对《香港增补字符集》(HKSCS, Hong Kong Supplementary Character Set) 的 2015 年版修订工作即将结束,香港用字的字形数量,特别是要增补到「基本多文种平面」中日韩统一表意文字主区后面的数量已经非常有限,要等最后的结果出来。而且同时《香港电脑汉字参考字形》也在制定过程中,因此为了切实支持香港用字需要,不得不推迟这部分的工作。也希望大家继续关注思源宋体的后续更新。
思源黑/宋这类屏幕字体,当印刷内文字体用,靠谱吗?
思源系列从来没有自称只是一套「屏幕字体」。Adobe 在其《思源宋体设计指南》里指出「我们开发思源宋体的目标是制作一款新的宋体字,让它的排版效果不仅在印刷纸面上,在平板或者手机的小设备上显示出来也能充分易读、实用。」所以,思源宋体这是一款同时胜任「印刷」「显示」的一款「泛用型」的字体,而不是舍其一。这套字在制作时并没有因为像一些「屏显字体」那样压缩细节,而且,和其他 CFF OpenType 字体一样,其针对屏显的「渲染提示」也是轻微的。实际上,出于其高质量的 PostScript 曲线制作原理,这套字的曲线精度完全可以胜任从海报到正文的各种高品质印刷输出。而正如上文提到的,在本次设计中又增加了对数字设备显示的优化,是让其在保持良好印刷品表现的基础上,在屏幕上能有更为良好的表现。
我在用思源黑体的时候行距一直有问题,思源宋体怎么样?
思源黑体的早期版本一直收到用户关于有行距过高、软件中文字框过大等问题反馈。经过 Adobe 方面的测试,已经在新版本进行了改进。而最发布的思源宋体就已经把 OS/2.sTypoLineGap 的数值设置成 0(而不是 1000),而 OS/2.usWinAscent 和 OS/2.usWinDescent值的计算也避开了一些具有超大高度、长度的特殊字符。这些做法都是尽量确保在跨平台使用的默认行距(即「纵向量度」)。然而,各个平台各个软件对于行高、文字外框的计算方法依然不一致,根据不同环境还是出现不同情况。用户可以继续进行测试,并期待那些尚未对应的应用在未来更新适配。
思源宋体完全支持竖排吗?
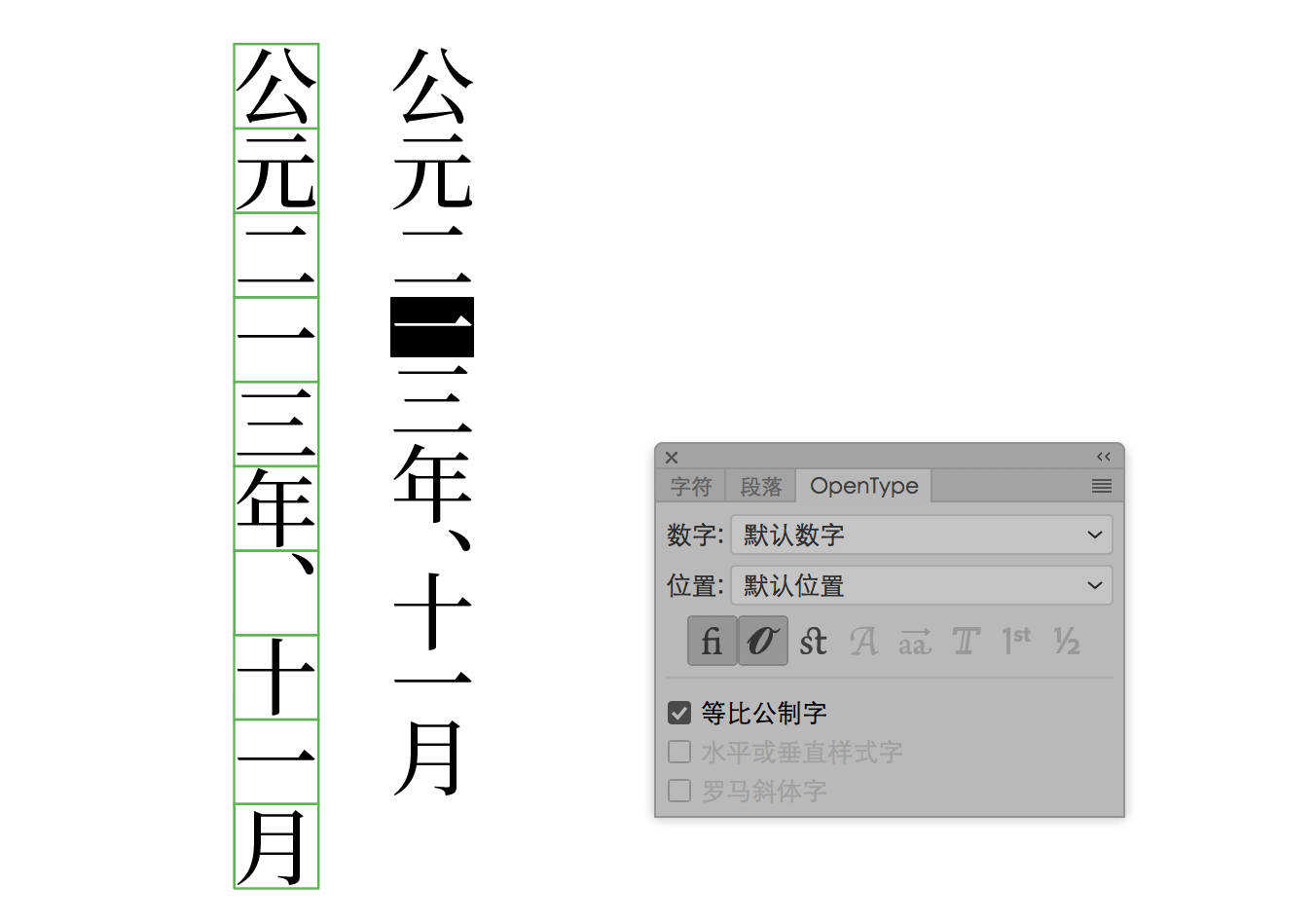
是的。谈到竖排支持,就必须提 UAX #50 (Unicode Vertical Text Layout) ,这份文档详细阐述了 Unicode 各个文种对竖排的需求。这份文件目前是 Unicode 的「技术报告」,但将于今年夏天正式提升为 Unicode 10.0 的标准附件,而思源宋体是率先支持这一规格的字体之一。反过来说,竖排的各种行为严格按照这份文档规定的特性来定义。
根据规格,Adobe 推荐只调用 GSUB 特性中的 vert 特性即可。而 vrt2 的 GSUB 特性其实都包括在 vert 里了,思源宋体保留这一特性只是出于对某些环境如 Windows 以及某些微软的一些应用的兼容需要。
值得一提的是,这次思源宋体里还专门配备了竖排专用假名,并能自动切换。竖排假名的尺寸约为横排假名的 98%,能够改善日文长文竖排的字面效果。
思源黑体的标点符号位置有点奇怪,思源宋体怎么样?
作为泛中日韩字体,对配合繁简中文和日韩中对标点的不同需求,思源系列的标点符号的处理有非常复杂的设计。思源黑体的标点在发布后收到很多用户反馈,因此 Adobe 在思源宋体制作伊始就针对标点的形态、位置进行了反复测试和配置。
在造型方面,思源宋体为中日韩的方块字搭配而新设计了问号造型,原 Source Serif Pro 的西式问号则作为选配调用。在位置方面,设计师们仔细查验了各种标点在虚拟字框的相对位置,在保持视觉平衡的同时,确保不同文种、横排竖排等的不同配置需求。

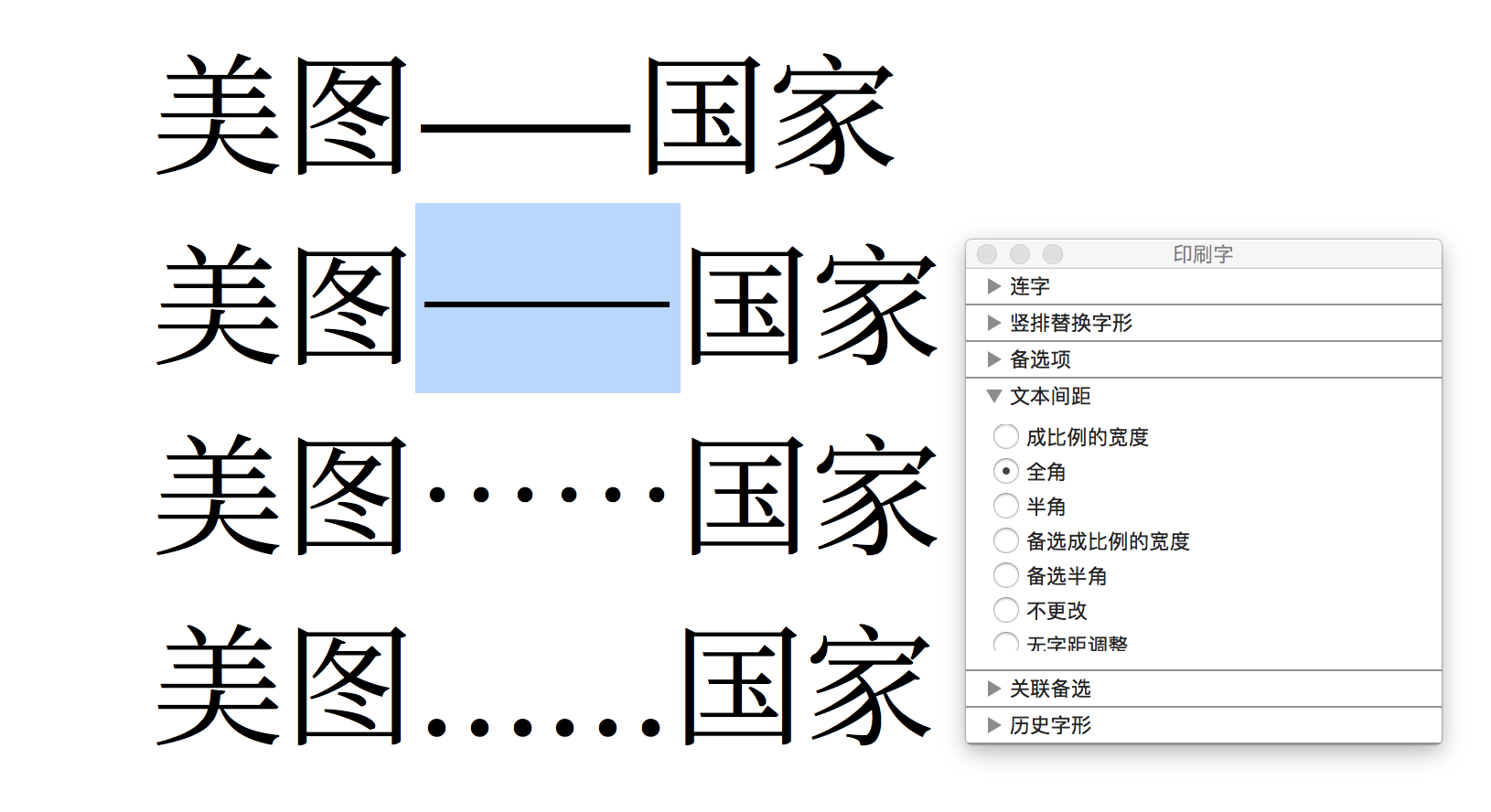
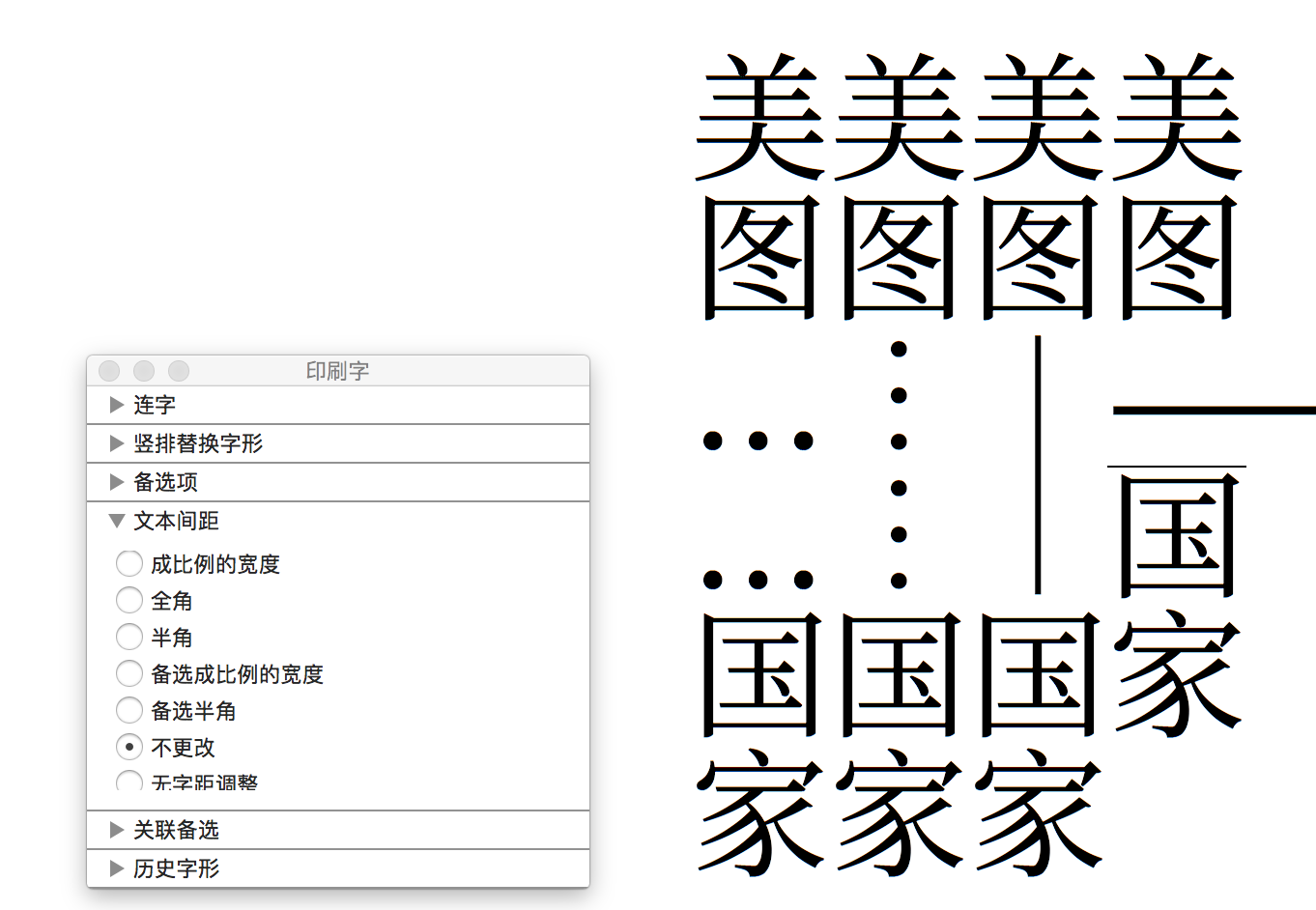
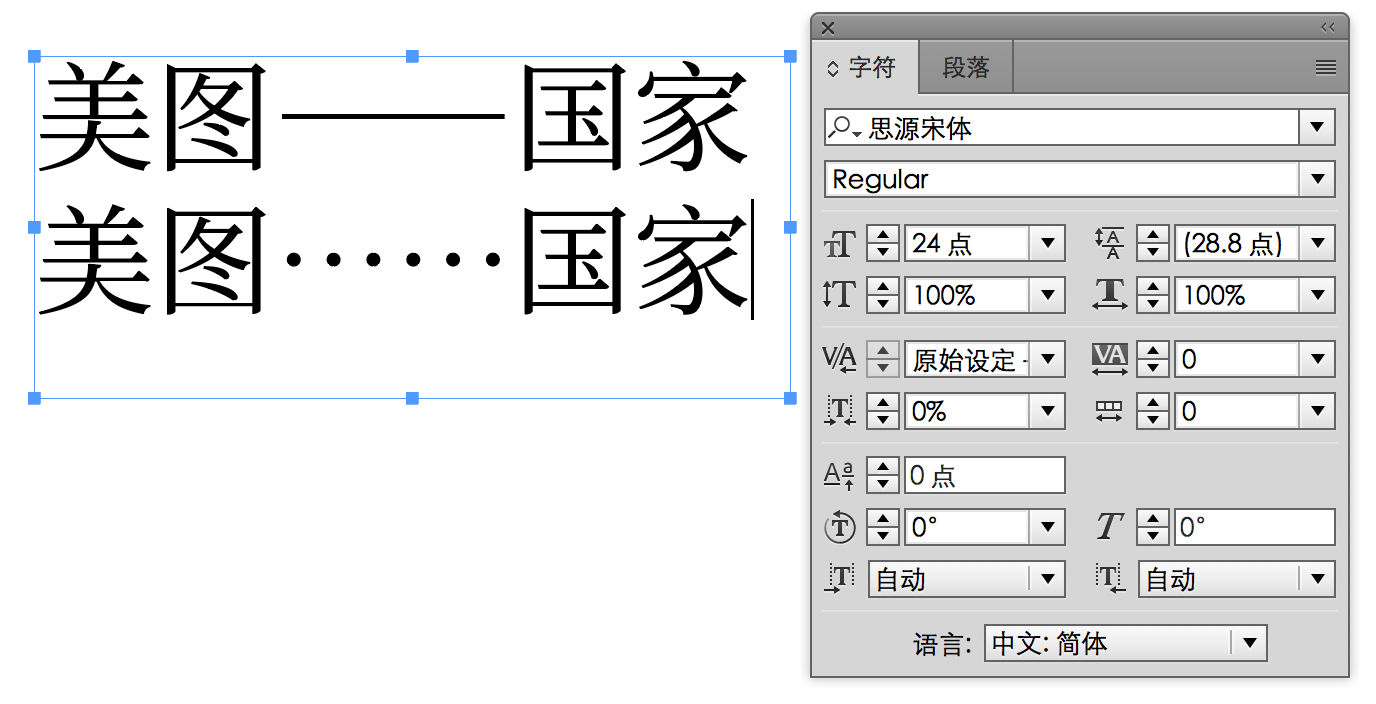
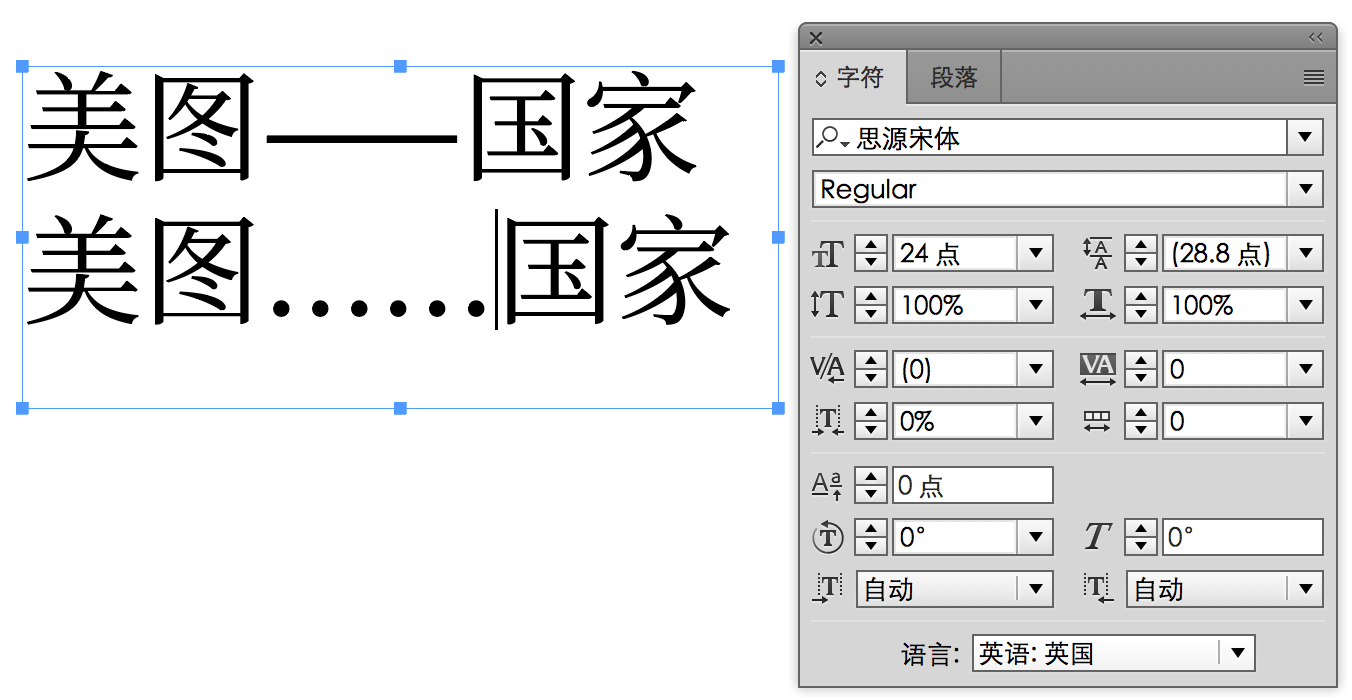
和思源黑体一样,破折号和省略号同时配备西文版(比例宽度)和中日韩版(全角),二者在造型(长度、粗细)和位置(基线对齐,或者虚拟字身居中)等方面都有不同。
上述这些特性,均需要通过在对 OpenType locl、pwid、hwid 等特性完全支持的环境(比如 macOS)或者应用程序(比如 Adobe InDesign)下才能进行正确调用,尤其是竖排。各种标点详细设置可以信息可以参考 Adobe《官方字体 readme 文件》。
既然思源宋体的西文部分来自 Source Serif Pro,那么装了思源宋体就不用 Source Serif Pro了?
思源宋体的西文部分来自 Source Serif Pro,但针对中日韩做了优化,因此二者不完全一样,用户应该需要选择使用。西文部分由 Source Serif Pro 设计师 Frank Grießhammer 亲手修改配置。
首先,拉丁字母部分在字形上进行了扩充,不仅支持 ASCII 和 ISO Latin 1,也对于越南文以及包括汉语拼音在内的中日韩罗马字转写所需字形进行了完全支持。另外,和某些国内字体厂商的习惯不同,思源宋体内含的希腊字母和西里尔字母都是比例宽度的,可以用来进行正常的俄文等文种的长文排版。
其次,原版 Source Serif Pro 只有六款字重,粗细分布也并不能和思源宋体直接搭配,因此设计师按照思源宋体的七个字重,对 Source Serif Pro 的粗细重新进行了内插值生成并调节。
再次,为配合中日韩混排,原 Source Serif Pro 的字形被放大到 107.5%(ExtraLight) 到 113.3%(Heavy)。因此同样字号下,思源宋体里的西文要比原版 Source Serif Pro 的字要大。
根据中日韩字体的需求,思源宋体的拉丁字母有「全角」「半角」和「比例」三种字形,用户可以根据需要调用相应的字形。注意「半角西文」和「比例西文」是两个不同的概念,「半角」西文是完全等宽的(宽度为中日韩方块字虚拟字身的一半),而「比例」才是真正的西文不等宽字形。

另外值得一提的是,一般西文字体里的数字都会比大写字高矮一些,并附有旧式数字。而思源宋体附带的数字出于对中日韩方块字的适配考虑,没有旧式数字,但是却额外配备了一套与大写字母等高的数字。用户同样可以根据需要选择调用。

思源宋体有字偶距信息吗?
有。在 kern 的 GPOS 特性里,设计师针对每款字重,比例拉丁字母、希腊字母、西里尔字母和日文假名的字偶对,以及中日韩标点都配有字偶间距信息。除此之外,日文假名和中日韩标点还配有 vkrn 数据供竖排时的字偶间距调整调用。
另外与「字偶距」没有直接关系的一点是,由于思源系列字体对标点符号和部分汉字设置有「比例量度」(Proportional Metrics,注意此术语在 Adobe 软件中错误被翻译成「等比公制字」),因此在 Adobe 软件里「字偶间距」调整选择「自动」时会将这个数值叠加而导致字距看起来有变化。用户可以在根据需要在软件方选择不同的字距调整方式自行调整,以达到期待效果。
TIB 团队在这套字的开发里发挥了什么作用?
和思源黑体一样,TIB 团队受 Google 国际化组的邀请作为外部测试人员,从 2015 年起到 2017 年最后发布,对四个内测版本和两个候选版分别进行了简体中文部分的测试反馈。其中梁海作为联系组长,与钱争予和 Eric Liu 等人对字重分配、标点配置、笔形调整等提出了很多建议和意见。另外,Eric Liu 同时又作为 Adobe 日本公司的特邀顾问,直接和小林剑博士以及 Adobe 东京团队进行了四次设计会议,前期对于简体中文笔形库、字形规范,后期与 TIB 成员一起就汉字设计的统一性和整体调整提出了诸多具体意见。Google 和 Adobe 公司双方都表示,TIB 成员提出的专业意见提高了思源宋体的设计质量,对成员的付出表示了衷心感谢。

下载这套字体时要注意什么问题?
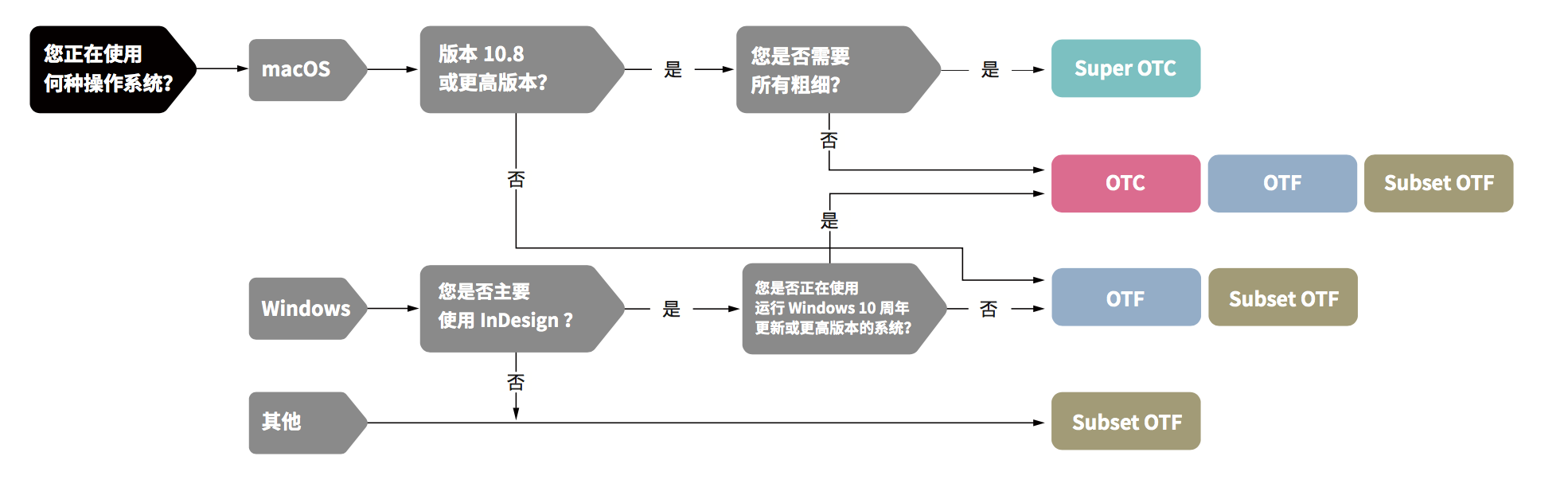
和思源黑体一样,这套字的实际部署版本非常多,请在下载之前一定要阅读《官方下载指南》。作为一款泛中日韩字体,最理想的版本还是使用 Super OTC 版本,对于 Mac 用户来说 macOS 10.8 及以上版本即可支持,而 Windows 则要 2017 年 4 月 11 日新发布的 Windows 10 Creators Update (Redstone2) 才能使用。
对于没有这样环境的其他用户,还有那些多数并不同时需要四个文种的用户(比如只需要简体中文),或者不需要所有七款字重的用户,思源宋体和黑体都有其他格式(OTC,OTF,SubsetOTF)的封装。通过《官方下载指南》里的流程图能够更快更准确地决定到底需要下载哪一款格式。
这套字可以商用吗?需要声明吗?
和思源黑体一样,这套字体也是通过 SIL Open Font License (OFL) v1.1 许可完全免费、开源的。因此无论家庭使用或者商用均不受限。开发者还可以利用源代码进行改造成自己新的字体进行再发布。
我发现了一些问题,应该到哪里去报告?
在 GitHub 上,Google 有 Noto font 专页 ,而 Adobe 的Source Han Serif 专页是由小林剑博士本人亲自维护,所以推荐大家直接在这上面进行讨论并报告相关问题 (issue),以便在版本更新的时候加以改进。
相关链接
- 思源宋体 Adobe Typekit 上的官方链接
- Noto Serif CJK Google 开发者官方博客
- 小林剑:Adobe CJK 博客《思源宋体的开发历史》

{kind=link}
10 个相关讨论
应该是 Source Han Serif 吧, 不是 Noto.
>Stark Shaw: 笔误已改,感谢指正
是啊,「본명조」转写成汉字就是「本明朝」,恰好和森泽的一款字同名。我之前去GitHub上面提issue被close了……尽管今天没有一个字符identical,但是以长远的背景来看,这两个名字就是一模一样的,这绝对是命名冲突,日文「本明朝」再转写到韩文也不是完全避免了冲突可能,只是韩国人现在不会愿意承认这个汉字词,也不清楚谚文的历史定位。小林剑博士也是揣着明白装糊涂吧。
>Celestial Phineas: 命名这件事情还有市场和法务考虑,永远不可能让所有人都满意的。韩国人现在都不用「谚文」这个词了,日文名称都是音译(比如日本的「本明朝」尽管可以叫 모도 명조),你也没法替他们操心。
感谢 Eric 的丰富详细讲解,就是有一疑问:「源ノ明朝(げんのみんちょう)」罗马字是「Gen-no-minchō」,为什么「小塚明朝(こづかみんちょう)」罗马字是「Kozuka Mincho」而不是「Kozuka Minchō」呢?
> Thomas B Tang: 原来小塚明朝的罗马字是 Kozuka Minchō, 长音符可省。但我这里的本意不是注罗马字音,而是写其英文名。给日语读音罗马转写和英文名是两回事。
中间的那个徽章特别漂亮,是 Adobe 为你们内部人员专门做的吗?
>zsy: 那是 Adobe 日本 4/10 在东京举办记者招待会时现场分发的纪念品之一
感谢分享,让设计师快速上手新的思源字体特性。深度和专业精神不是各种业余新闻可以一概而论的。
若是眞的爲了切實支持香港用字需要,就應當聆聽和採納眞正香港用戶的意見。香港用戶習慣的字形有兩種:一種是傳承字形/舊字形,大體就是康熙/過往彫版/明體字粒那種字形;另一種是儷式字形,華康儷宋、蒙納宋那種。至於所謂的字形標準,其實並不存在於香港人生活裏,香港的敎育字形參考是用來以筆去寫、方便小學寫字敎學所需的,不是用來設計給印刷所需的,那參考標準本身更強調只是作為參考,不要排斥異體字和不同寫法。與台灣那種盲目高舉教育標準的做法大相逕庭。香港用戶這點聲明早就反映過,只是小林劍不採納,同時又被台標粉絲惡意攻擊而已。
5 个Trackbacks
[…] 撰文解答关于 Noto Serif CJK / Source Han Serif 的疑问,刊于 Type is […]
[…] 今年 4 月份 Google 和 Adobe 联合发布了思源宋体,继思源黑体之后的又一款开源的泛 CJK 字体,这款高质量的字体对于各行各业的设计师来说无疑是一份馈赠,也是对开源意识的激励。如果初略去审视这款字体,有两个明显的特征,一个是字体的框架结构区别于传统的宋体,更接近黑体,如中宫大、重心低等特征;另一个特征就是字体轮廓的曲线特征,即贝塞尔曲线的绘制结构和策略。思源宋体的轮廓绘制使用了简洁并求效率的方式,除了特殊的笔画,基本采用单条曲线(即头尾两个节点)完成,就像是“丶”,有着较大走势变化的形状,也使用单条曲线绘制完成,这样带来的结果是,过度拉长其中一条曲线的控制点手柄,就像“要”字的长点的尾部,思源宋体就靠单条曲线完成大弧度,选择此种曲线绘制策略应是综合了对效率的考虑,如果只是从形态角度来考虑,这种绘制方式当然不会是最佳的选择。 […]
[…] 关于思源宋体的问答 […]
[…] Liu,关于思源宋体的问答, […]
[…] 年 Adobe 公司发布的泛中日韩字体「思源」系列就采用了一个相对激进的做法:第一步先使用 OpenType 中的「字形组合」ccmp 特性(即 Glyph […]