


微博曾出現過兩個看起來一模一樣的「微博話題」,而實際上是其中一個話題里的漢字錯用了康熙部首。這樣的文本內容,如果遇到不支持康熙部首的字體,系統會回退到用默認字體顯示,突出了字形的不一致,讓用戶察覺。其實,這些康熙部首都是「兼容字符」,能不用就不用,更不應該用其去代替正常的漢字。

「部首」是指為漢字分類的基本構件。最早是東漢的許慎在《說文解字》中將漢字分為 540 部。清朝康熙年間編撰的《康熙字典》確立了 214 個部首。這一分類方式沿用至今,尤其是港台和日本的漢字字典大多仍沿用 214 部首的分法。
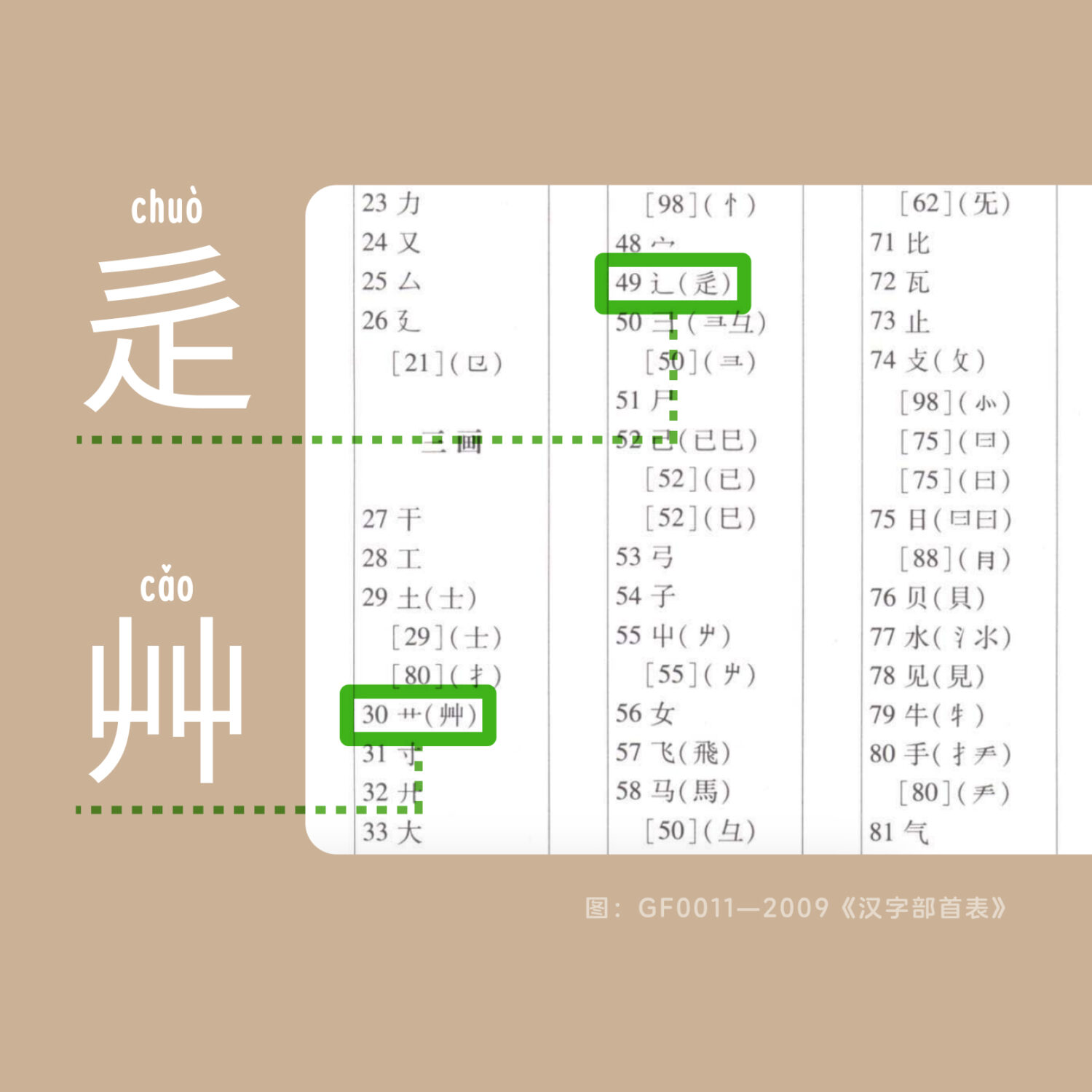
然而,隨着漢字的簡化推廣,傳統部首難以適應現代需求。2009 年中國和國家語委聯合發布了《漢字部首表》,對部首進行了重新定義,將原有的一些傳統部首作為附形部首處理。如上,三畫的「辶」、「艹」被列為主部首,而傳統的「辵」、「艸」則被歸為附形部首。
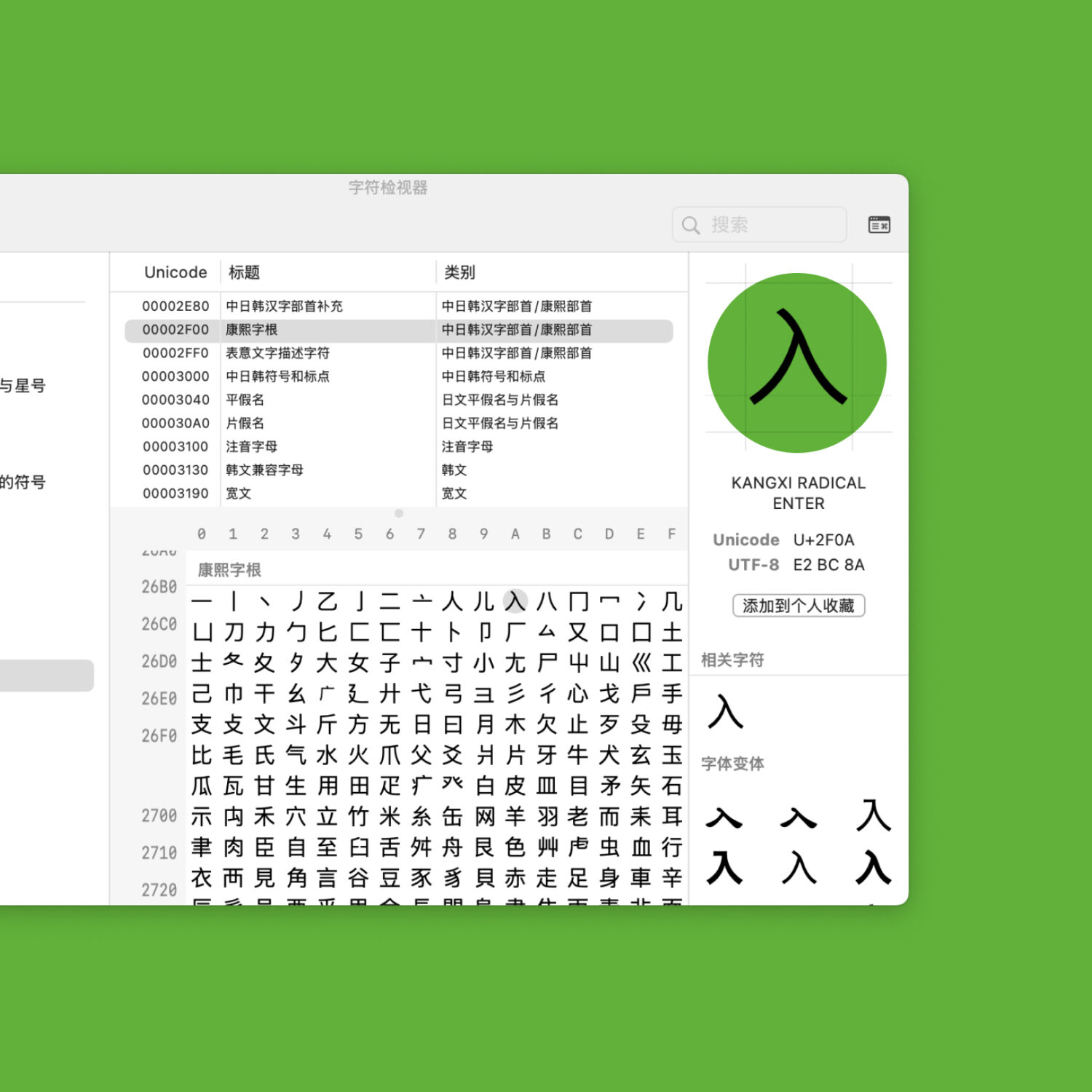
Unicode 自 2000 年發布的 3.0 版起,在 U+2F00 至 U+2FDF 的位置安放了 214 個康熙部首。因為之前台灣標準《中文標準交換碼》CNS11643―1992 已在漢字之外另開碼位收錄了康熙部首,所以 Unicode 按照「源字集分離原則」也必須另開碼位全部收入,才與其台灣標準兼容。

{kind=link}