


2017 年 4 月 3 日(北京時間 4 月 4 日)Google 和 Adobe 聯合發布了他們共同合作的第二款完全免費開源的「泛中日韓字體」,成為設計界、技術界的一大新聞。這套字由七款字重構成,內含字形達到了 OpenType 規格上限的 65 535 個。由於整個項目的內容非常龐大而複雜,涉及商業合作、開源版權、字體設計、文字編碼、工程技術等多方面的內容,大家在好奇的同時不免也會產生了不少疑問。針對中文媒體上存在一些不甚準確的說法,我們在此用問答的形式對這套字加以說明,供大家在使用、開發時參考。
這套字體到底叫什麼名字?
與 2014 年發布的第一個項目一樣,這個項目的成果也是「一套字體兩個名字」,兩家公司分別按照自己的品牌進行包裝:Google 方面把它作為 Google Noto Fonts 項目里 Noto CJK 的一部分,將這次發布的字體命名為 Noto Serif CJK;而 Adobe 方面將其作為該公司字體開源項目 Source 系列裡 Source Han 的的一部分,將這次發布的字體命名為 Source Han Serif。
Google 的 Noto 系列名稱,來自其「消滅豆腐塊」(no more tofu, □) 讓字符都能正常顯示的願景。此項目已經覆蓋了全球眾多文種,其中絕大部分是 Google 與 Monotype 公司合作的,而與 Adobe 合作的東亞部分明顯是引用了 Unicode 中「中日韓統一表意文字」的術語(雖然實際上是 CJKV「中日韓越」),在名字里加了 CJK 這三個字母。
出於其完全開源、免費的性質,Adobe 將這個系列命名為 Source,所以單純說 Source Serif,指的是 Adobe 另外一套開源的西文襯線字體;而只有說 Source Han Serif,才是指這款泛中日韓字體——很顯然中間的 Han 不能隨便省略,否則會指代不明。
與 Google 不同,Adobe 還為各個區域分別起了本地化的名字:中文名字從 Source「源」的含義而來,無論繁簡都稱作「思源宋體」(注意不是「明體」),這和「思源黑體」一樣,命名也有「飲水思源」的用意;在日文則稱作「源ノ明朝」(げんのみんちょう、Gen-no-minchō),既避免了音譯之後與「甜醬 (sauce)」相混,「源」字不訓讀成「みなもと」(minamoto) 而用音讀的「げん」(gen) 也順利解決了商標註冊申請問題,中間加上片假名「ノ」還可以向吉卜力動畫片致敬;而韓文名稱「본명조」(Bon-myeong-jo) 按照韓文漢字寫出來其實就是「本明朝」,即「根本」的「本」。
請注意,「襯線」「無襯線體」(Serif/Sans Serif) 原本是西文字體里的概念,我們只是其風格對應到中文的「宋體/黑體」,日文的「明朝體」「ゴシック體」也是這樣。儘管字體風格上類似,但從字體設計的嚴格定義上來說「西文襯線體=中文宋體=日文明朝體」是不太恰當的。
為行文方便,如果沒有特別指出,下文通稱「思源宋體」。
Google 版和 Adobe 版有什麼區別?
如上所述,Google 版的 Noto Serif CJK和 Adobe 版的思源宋體的區別只在於名字,因此實際的 OpenType 字體文件 name table 里關於版權、廠商的相關數值分別寫進了兩家公司的內容。另外,為了迴避Android 系統上的 bug,Noto 版本中 U+2252 (≒) 和 U+25C8 (◈) 這兩個碼位沒有映射到字形上。除去這些細節方面,二者完全沒有區別。
真的沒豆腐嗎?這套字到底覆蓋了多少字?
Google「沒有豆腐塊」的願景是好的,但由於現在 Unicode 收字已浩如煙海,一套字不可能完整覆蓋所有中日韓漢字。按照 Google 官方網站上的說明,這套字只是「完全覆蓋了 Unicode 里『基本多文種平面』(BMP)的中日韓表意文字,並為支持中國和日本的標準,對第二平面提供了有限支持。」
我們最關心的「中日韓統一表意文字」里只有主區(20 914 字)和「擴充 A 區」(6582 字)在「基本多文種平面」裡面。剩下的擴充 B、C、D、E(以及即將發布的 F)區都在第二平面上,因此都是「有限支持」。
另外,從「字形」的角度分別來看四個文種的情況:
| 文 種 | 字形數 | 支 持 標 准 |
| 簡體中文 | 30 995 | 所有 GB18030 漢字和《通用規範漢字表》 |
| 繁體中文 | 16 383 | 所有大五碼漢字以及七個倚天碼漢字 |
| 日 文 | 17 875 | 所有 Adobe-Japan1-6 日本漢字 |
| 韓 文 | 24 752 | 所有現代(11 172 個)和常用古代(500 個)韓字音節和「可組合韓字字母」,還有全部 KS X 1001 與 1002 的(7476 個)韓文漢字以及增補的 466 個韓文漢字 |

相信大家已經看到,如果將上表四個字形數量單純相加會超過九萬,而一個 OpenType 字體文件的上限只能收到 65 535 個字形,因此思源項目需要將中日韓里一樣的字形進行共享,否則無論如何都是放不下的。思源宋體的設計師針對 Unicode 的 43 029 個碼位放置了六萬多個字形,比如在 14 697 個碼位上採用了四個區域完全相同的字形共享,而在 270 個碼位(都在「基本多文種平面」裡面)上放置了四個區域各不相同的字形。剩下的碼位也是按情況分別判斷是共享還是分開,逐一安置。另外,這套字配備了從 Extralight 到 Heavy 共七款字重,因此要配置的字形達 46 萬個之多,這就是這個項目龐大而複雜的原因。
作為簡體中文用戶,我想知道「思源宋體」收的字和 GB 18030 以及《通用規範漢字表》到底是什麼關係?
從上表可以看到,思源宋體支持簡體中文的字形數量是 30 995 個。而 GB 18030–2000 字彙里收的 27 533 個漢字都在「基本多文種平面」裡面,因此「思源宋體」是完全支持的。
另一方面,中國國務院 2013 年發布的《通用規範漢字表》里規定了 8105 個規範字,而這其中有 199 個規範字超出了 GB18030–2000 範圍。其中有 196 個分別落在擴充 B、C、D、E 區 ,還有三個規範字(U+9FCD 鿍、U+9FCE 鿎、U+9FCF 鿏)後來在 2015 年發布的 Unicode 8.0 版本增補到了「基本多文種平面」里。由於思源字體對這些字做了特別對待的「有限支持」,因此都可以正常顯示。單從字形覆蓋這一點,對比中國商業字體的現狀,可以說思源宋體已經走在中國字體產品前列。
「中文部分由華文製作」這種說法對嗎?
思源宋體製作由 Adobe 公司的小林劍博士總負責,並由日本 Adobe 的字體團隊具體操作,包括主設計師

和思源黑體一樣,常州華文公司設計製作了繁體中文和簡體中文字形,數量極其龐大。但是,由於思源項目中日韓的字形有複雜的共享關係,有的字形可以拿到繁簡日韓四個版本共享,有的卻不行。最後的成品中,簡體中文裡有些字形是從日文共享過來的,並不是華文製作的;反過來在日文里也有些字形是華文做的,因此嚴格來說不是完全的一一對等關係。
這套字的開發製作前後耗費了多長時間?
思源宋體的實際設計開發工作於 2014 年底,也就是思源黑體發布後的幾個月就已經開始着手。華文在 2015 年中期開始了中文字形的製作,之後經過四個內測版和兩個發布候選版 (Release Candidate),最終於 2017 年 4 月發布,實際發布時間比原先計劃推遲了兩三個月。
那個 biáng 到底是什麼?為什麼字符串里有好多虛線框框?
這次思源宋體發布新聞里,轉載率最高的莫過於其中的一個彩蛋:對 biáng 字的支持。拷貝下述字符串,選擇思源宋體即可顯示。當然,中日韓版本的字形也不盡相同。
-
- (繁體)⿺辶⿳穴⿰月⿰⿲⿱幺長⿱言馬⿱幺長刂心
- (簡體)⿺辶⿳穴⿰月⿰⿲⿱幺長⿱言馬⿱幺長刂心

陝西關中地區的這道知名傳統風味麵食的名稱據說是書寫最複雜、筆畫最多的漢字之一,最常見字形有 56 畫,而實際上還有繁體、簡體等不同版本。此字還沒有進入 Unicode,但是相關提案已經提交,預計會收入中日韓統一漢字的擴充 G 區。
這個字形其實早在 2015 年就已經畫好了,而 Adobe 製作這個字的原因其實很簡單:首先是為了對其內部造字系統「表意文字筆形庫」(Ideograph Element Library) 進行壓力測試;而另外一個目的則更為實際,因為 2015 年當時小林劍博士向 Unicode 技術委員會遞交這個字編碼提案的報告里需要這個顯示字形。
大家首先好奇的是這個序列里莫名其妙的虛線框框是什麼東西。這當然不是亂碼,而是 Unicode 規範里的「表意文字描述符」(Ideographic Description Character,IDC),碼位在 U+2FFx 這一列上。這些描述符的原理很簡單,比如「⿰木目」表示將「木」「目」兩個部件左右組合,組合結果就是「相」。這套組合符一共有十二種,可以多個疊加使用。採用這種方法可以將這些尚未編碼的漢字以文本代碼的方式記錄下來,為將來查找替換提供極大便利。
從技術上來說,思源宋體只是提前為這個還沒有正式 Unicode 碼位的字預先描繪好了字形,然後通過 OpenType 特性設置之後供應用軟件調用而已。這並不是一個高新科技,因為這些特性早在二十年前 OpenType 發布時候就已經有了。
需要強調的是,思源宋體里採用的並不是 liga(Standard Ligatures,標準合字)特性,而是 ccmp(Glyph Composition / Decomposition,字形組合/分解)的 GSUB 特性來進行調用的。這樣的考慮是因為 liga 特性要依靠用戶端手動去開啟關閉,而 ccmp 特性是默認打開的。具體細節可以看小林劍博士的博客文章。
無論用字體方面採用什麼特性,最後還是需要客戶端環境的支持。支持ccmp 特性的環境並沒有 liga 特性多。比如,雖然在 macOS 系統層級就可以支持顯示這個字,但在目前最新版的 Word for Mac 里卻依然無法成功調用。因此,這個彩蛋能否正常顯示,需要在各個系統、應用測試確認。
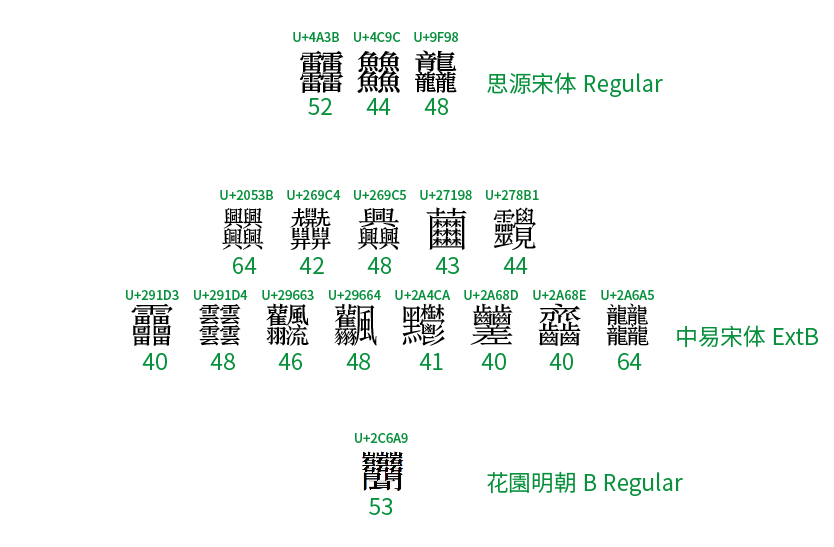
另外,這個字其實並不是筆畫數最多的字。事實上,Unicode 里已經收了有很多筆畫數超四十的漢字,下面是其中一部分(括號里是其筆畫數):
- 思源宋體支持的擴充 A 區: 䨻 (52), 䲜 (44), 龘 (48);
- 超出思源宋體支持的擴充 B 區: ? (64), ? (42), ? (48), ? (43), ? (44), ? (40), ? (48), ? (46), ? (48), ? (41), ? (40), ? (40), ? (64)
- 超出思源宋體支持的擴充 E 區: ? (53)。
考慮到各種環境不一定能正常顯示,特將上述字符用圖片顯示如下:
思源宋體在設計上什麼特點?
由於設計本身是基於 Adobe 公司在 1998 年發布的日文字體「小塚明朝」(Kozuka Mincho) ,思源宋體的字形和「小塚明朝」一樣,都是用該公司統一配備的「表意文字筆形庫」分發給包括華文在內的合作廠商進行拼字設計而成的。筆形庫里的筆形總數達 187 種,其中還包括針對簡體中文增加的一些特殊筆形(如「撇點」)。



思源宋體與我們常見的以「宋二」為基礎的老版數碼字體相比,中宮更大、重心更低。但是和原版「小塚明朝」相比,思源宋體的中宮進行了約 98% 的縮小處理,而為屏幕背光顯示的需要將原本較細的橫畫適當進行了加粗。其設計介於傳統宋體和現代宋體中間,但總體來說略偏現代。



思源宋體的筆形完全符合規範么?
思源宋體簡體中文的字形基本依照《通用規範漢字表》的寫法。但由於 2013 年發布的《通用規範漢字表》本身沒有對字形作出明確詳細的解說,因此對於一些筆畫的處理是到底「字形差異」還是「設計差異」並無法判斷。比如對於「四」「西」等漢字里豎彎與右框是否接觸的問題,似乎規範字形本身就沒有統一,而思源宋體則出於設計考慮處理成「全接觸」。
同樣的問題也出現在繁體中文裡。思源宋體繁體中文版中「口」的雙腳出頭、立字中的兩筆上下是否接觸、糸字旁下面三點朝向、言字旁上方兩筆是否相觸等等,都和「細明體」的處理方法不同,儘管這些細節在台灣「國字標準字體」里其實並沒有明文規定。總體來說,思源宋體的處理方法屬於「設計差異」範疇。


這次思源宋體發布的繁體中文採用的是台灣的字形標準,為什麼沒有香港版?
的確,這次發布的繁體中文是按照台灣的字形標準製作的。香港字形版已經在計劃中,但是要放到第二版才會發布。主要原因是,香港特別行政區的中文界面諮詢委員會工作小組正在對《香港增補字符集》(HKSCS, Hong Kong Supplementary Character Set) 的 2015 年版修訂工作即將結束,香港用字的字形數量,特別是要增補到「基本多文種平面」中日韓統一表意文字主區後面的數量已經非常有限,要等最後的結果出來。而且同時《香港電腦漢字參考字形》也在制定過程中,因此為了切實支持香港用字需要,不得不推遲這部分的工作。也希望大家繼續關注思源宋體的後續更新。
思源黑/宋這類屏幕字體,當印刷內文字體用,靠譜嗎?
思源系列從來沒有自稱只是一套「屏幕字體」。Adobe 在其《思源宋體設計指南》里指出「我們開發思源宋體的目標是製作一款新的宋體字,讓它的排版效果不僅在印刷紙面上,在平板或者手機的小設備上顯示出來也能充分易讀、實用。」所以,思源宋體這是一款同時勝任「印刷」「顯示」的一款「泛用型」的字體,而不是舍其一。這套字在製作時並沒有因為像一些「屏顯字體」那樣壓縮細節,而且,和其他 CFF OpenType 字體一樣,其針對屏顯的「渲染提示」也是輕微的。實際上,出於其高質量的 PostScript 曲線製作原理,這套字的曲線精度完全可以勝任從海報到正文的各種高品質印刷輸出。而正如上文提到的,在本次設計中又增加了對數字設備顯示的優化,是讓其在保持良好印刷品表現的基礎上,在屏幕上能有更為良好的表現。
我在用思源黑體的時候行距一直有問題,思源宋體怎麼樣?
思源黑體的早期版本一直收到用戶關於有行距過高、軟件中文字框過大等問題反饋。經過 Adobe 方面的測試,已經在新版本進行了改進。而最發布的思源宋體就已經把 OS/2.sTypoLineGap 的數值設置成 0(而不是 1000),而 OS/2.usWinAscent 和 OS/2.usWinDescent值的計算也避開了一些具有超大高度、長度的特殊字符。這些做法都是盡量確保在跨平台使用的默認行距(即「縱向量度」)。然而,各個平台各個軟件對於行高、文字外框的計算方法依然不一致,根據不同環境還是出現不同情況。用戶可以繼續進行測試,並期待那些尚未對應的應用在未來更新適配。
思源宋體完全支持豎排嗎?
是的。談到豎排支持,就必須提 UAX #50 (Unicode Vertical Text Layout) ,這份文檔詳細闡述了 Unicode 各個文種對豎排的需求。這份文件目前是 Unicode 的「技術報告」,但將於今年夏天正式提升為 Unicode 10.0 的標準附件,而思源宋體是率先支持這一規格的字體之一。反過來說,豎排的各種行為嚴格按照這份文檔規定的特性來定義。
根據規格,Adobe 推薦只調用 GSUB 特性中的 vert 特性即可。而 vrt2 的 GSUB 特性其實都包括在 vert 里了,思源宋體保留這一特性只是出於對某些環境如 Windows 以及某些微軟的一些應用的兼容需要。
值得一提的是,這次思源宋體里還專門配備了豎排專用假名,並能自動切換。豎排假名的尺寸約為橫排假名的 98%,能夠改善日文長文豎排的字面效果。
思源黑體的標點符號位置有點奇怪,思源宋體怎麼樣?
作為泛中日韓字體,對配合繁簡中文和日韓中對標點的不同需求,思源系列的標點符號的處理有非常複雜的設計。思源黑體的標點在發布後收到很多用戶反饋,因此 Adobe 在思源宋體製作伊始就針對標點的形態、位置進行了反覆測試和配置。
在造型方面,思源宋體為中日韓的方塊字搭配而新設計了問號造型,原 Source Serif Pro 的西式問號則作為選配調用。在位置方面,設計師們仔細查驗了各種標點在虛擬字框的相對位置,在保持視覺平衡的同時,確保不同文種、橫排豎排等的不同配置需求。

和思源黑體一樣,破折號和省略號同時配備西文版(比例寬度)和中日韓版(全角),二者在造型(長度、粗細)和位置(基線對齊,或者虛擬字身居中)等方面都有不同。
上述這些特性,均需要通過在對 OpenType locl、pwid、hwid 等特性完全支持的環境(比如 macOS)或者應用程序(比如 Adobe InDesign)下才能進行正確調用,尤其是豎排。各種標點詳細設置可以信息可以參考 Adobe《官方字體 readme 文件》。




既然思源宋體的西文部分來自 Source Serif Pro,那麼裝了思源宋體就不用 Source Serif Pro了?
思源宋體的西文部分來自 Source Serif Pro,但針對中日韓做了優化,因此二者不完全一樣,用戶應該需要選擇使用。西文部分由 Source Serif Pro 設計師 Frank Grießhammer 親手修改配置。
首先,拉丁字母部分在字形上進行了擴充,不僅支持 ASCII 和 ISO Latin 1,也對於越南文以及包括漢語拼音在內的中日韓羅馬字轉寫所需字形進行了完全支持。另外,和某些國內字體廠商的習慣不同,思源宋體內含的希臘字母和西里爾字母都是比例寬度的,可以用來進行正常的俄文等文種的長文排版。
其次,原版 Source Serif Pro 只有六款字重,粗細分布也並不能和思源宋體直接搭配,因此設計師按照思源宋體的七個字重,對 Source Serif Pro 的粗細重新進行了內插值生成並調節。
再次,為配合中日韓混排,原 Source Serif Pro 的字形被放大到 107.5%(ExtraLight) 到 113.3%(Heavy)。因此同樣字號下,思源宋體里的西文要比原版 Source Serif Pro 的字要大。
根據中日韓字體的需求,思源宋體的拉丁字母有「全角」「半角」和「比例」三種字形,用戶可以根據需要調用相應的字形。注意「半角西文」和「比例西文」是兩個不同的概念,「半角」西文是完全等寬的(寬度為中日韓方塊字虛擬字身的一半),而「比例」才是真正的西文不等寬字形。

另外值得一提的是,一般西文字體里的數字都會比大寫字高矮一些,並附有舊式數字。而思源宋體附帶的數字出於對中日韓方塊字的適配考慮,沒有舊式數字,但是卻額外配備了一套與大寫字母等高的數字。用戶同樣可以根據需要選擇調用。

思源宋體有字偶距信息嗎?
有。在 kern 的 GPOS 特性里,設計師針對每款字重,比例拉丁字母、希臘字母、西里爾字母和日文假名的字偶對,以及中日韓標點都配有字偶間距信息。除此之外,日文假名和中日韓標點還配有 vkrn 數據供豎排時的字偶間距調整調用。
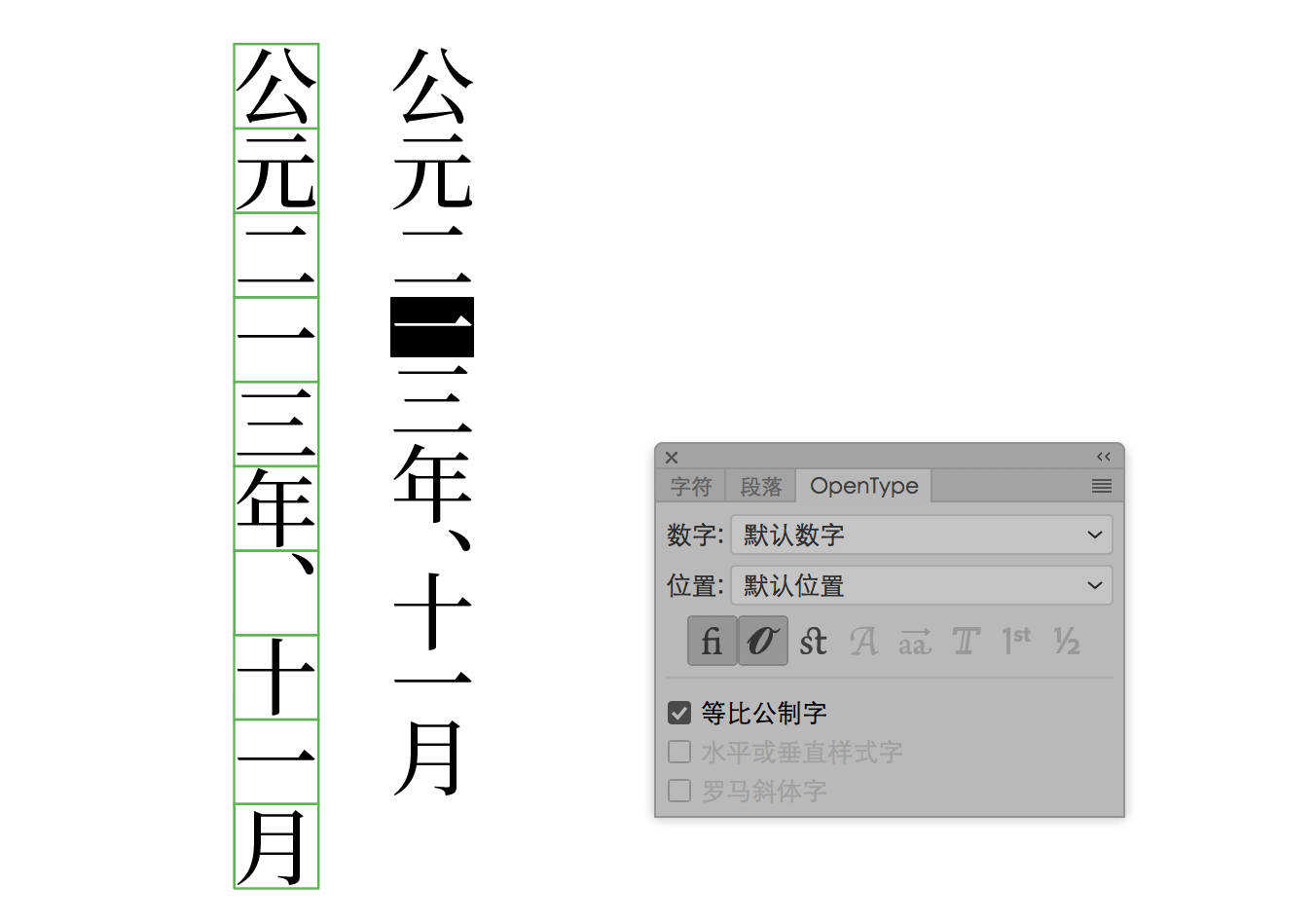
另外與「字偶距」沒有直接關係的一點是,由於思源系列字體對標點符號和部分漢字設置有「比例量度」(Proportional Metrics,注意此術語在 Adobe 軟件中錯誤被翻譯成「等比公制字」),因此在 Adobe 軟件里「字偶間距」調整選擇「自動」時會將這個數值疊加而導致字距看起來有變化。用戶可以在根據需要在軟件方選擇不同的字距調整方式自行調整,以達到期待效果。
TIB 團隊在這套字的開發里發揮了什麼作用?
和思源黑體一樣,TIB 團隊受 Google 國際化組的邀請作為外部測試人員,從 2015 年起到 2017 年最後發布,對四個內測版本和兩個候選版分別進行了簡體中文部分的測試反饋。其中梁海作為聯繫組長,與錢爭予和 Eric Liu 等人對字重分配、標點配置、筆形調整等提出了很多建議和意見。另外,Eric Liu 同時又作為 Adobe 日本公司的特邀顧問,直接和小林劍博士以及 Adobe 東京團隊進行了四次設計會議,前期對於簡體中文筆形庫、字形規範,後期與 TIB 成員一起就漢字設計的統一性和整體調整提出了諸多具體意見。Google 和 Adobe 公司雙方都表示,TIB 成員提出的專業意見提高了思源宋體的設計質量,對成員的付出表示了衷心感謝。

下載這套字體時要注意什麼問題?
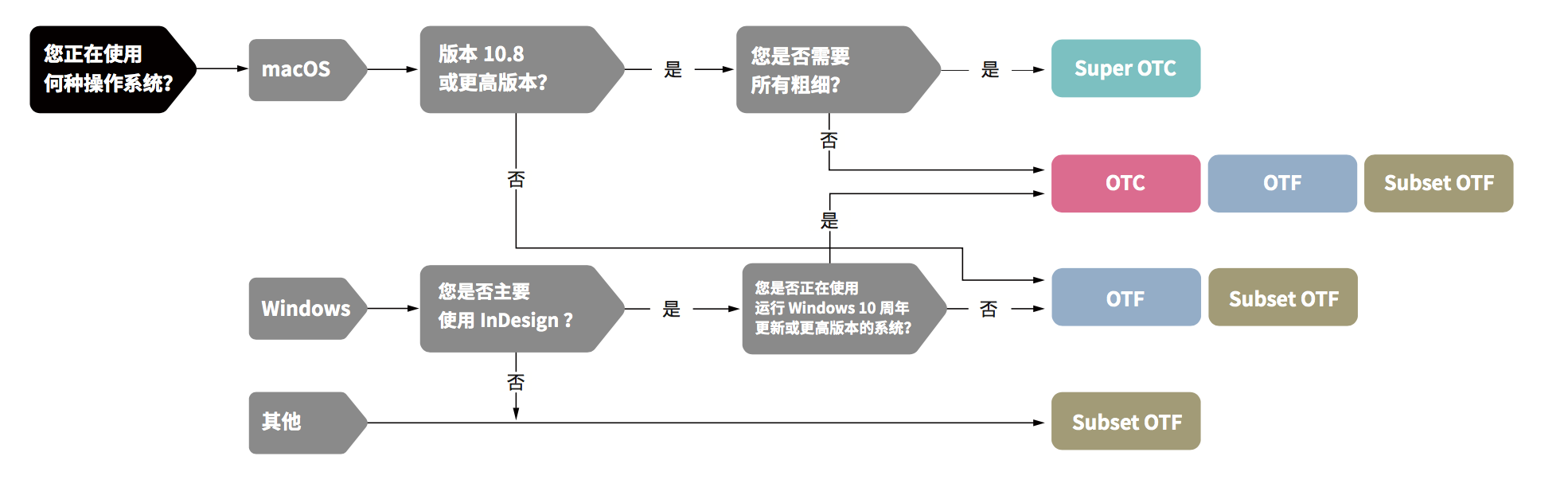
和思源黑體一樣,這套字的實際部署版本非常多,請在下載之前一定要閱讀《官方下載指南》。作為一款泛中日韓字體,最理想的版本還是使用 Super OTC 版本,對於 Mac 用戶來說 macOS 10.8 及以上版本即可支持,而 Windows 則要 2017 年 4 月 11 日新發布的 Windows 10 Creators Update (Redstone2) 才能使用。
對於沒有這樣環境的其他用戶,還有那些多數並不同時需要四個文種的用戶(比如只需要簡體中文),或者不需要所有七款字重的用戶,思源宋體和黑體都有其他格式(OTC,OTF,SubsetOTF)的封裝。通過《官方下載指南》里的流程圖能夠更快更準確地決定到底需要下載哪一款格式。
這套字可以商用嗎?需要聲明嗎?
和思源黑體一樣,這套字體也是通過 SIL Open Font License (OFL) v1.1 許可完全免費、開源的。因此無論家庭使用或者商用均不受限。開發者還可以利用源代碼進行改造成自己新的字體進行再發布。
我發現了一些問題,應該到哪裡去報告?
在 GitHub 上,Google 有 Noto font 專頁 ,而 Adobe 的Source Han Serif 專頁是由小林劍博士本人親自維護,所以推薦大家直接在這上面進行討論並報告相關問題 (issue),以便在版本更新的時候加以改進。
相關鏈接
- 思源宋體 Adobe Typekit 上的官方鏈接
- Noto Serif CJK Google 開發者官方博客
- 小林劍:Adobe CJK 博客《思源宋體的開發歷史》

{kind=link}
10 個相關討論
應該是 Source Han Serif 吧, 不是 Noto.
>Stark Shaw: 筆誤已改,感謝指正
是啊,「본명조」轉寫成漢字就是「本明朝」,恰好和森澤的一款字同名。我之前去GitHub上面提issue被close了……儘管今天沒有一個字符identical,但是以長遠的背景來看,這兩個名字就是一模一樣的,這絕對是命名衝突,日文「本明朝」再轉寫到韓文也不是完全避免了衝突可能,只是韓國人現在不會願意承認這個漢字詞,也不清楚諺文的歷史定位。小林劍博士也是揣着明白裝糊塗吧。
>Celestial Phineas: 命名這件事情還有市場和法務考慮,永遠不可能讓所有人都滿意的。韓國人現在都不用「諺文」這個詞了,日文名稱都是音譯(比如日本的「本明朝」儘管可以叫 모도 명조),你也沒法替他們操心。
感謝 Eric 的豐富詳細講解,就是有一疑問:「源ノ明朝(げんのみんちょう)」羅馬字是「Gen-no-minchō」,為什麼「小塚明朝(こづかみんちょう)」羅馬字是「Kozuka Mincho」而不是「Kozuka Minchō」呢?
> Thomas B Tang: 原來小塚明朝的羅馬字是 Kozuka Minchō, 長音符可省。但我這裡的本意不是注羅馬字音,而是寫其英文名。給日語讀音羅馬轉寫和英文名是兩回事。
中間的那個徽章特別漂亮,是 Adobe 為你們內部人員專門做的嗎?
>zsy: 那是 Adobe 日本 4/10 在東京舉辦記者招待會時現場分發的紀念品之一
感謝分享,讓設計師快速上手新的思源字體特性。深度和專業精神不是各種業餘新聞可以一概而論的。
若是眞的爲了切實支持香港用字需要,就應當聆聽和採納眞正香港用戶的意見。香港用戶習慣的字形有兩種:一種是傳承字形/舊字形,大體就是康熙/過往彫版/明體字粒那種字形;另一種是儷式字形,華康儷宋、蒙納宋那種。至於所謂的字形標準,其實並不存在於香港人生活裏,香港的敎育字形參考是用來以筆去寫、方便小學寫字敎學所需的,不是用來設計給印刷所需的,那參考標準本身更強調只是作為參考,不要排斥異體字和不同寫法。與台灣那種盲目高舉教育標準的做法大相逕庭。香港用戶這點聲明早就反映過,只是小林劍不採納,同時又被台標粉絲惡意攻擊而已。
5 個Trackbacks
[…] 撰文解答關於 Noto Serif CJK / Source Han Serif 的疑問,刊於 Type is […]
[…] 今年 4 月份 Google 和 Adobe 聯合發布了思源宋體,繼思源黑體之後的又一款開源的泛 CJK 字體,這款高質量的字體對於各行各業的設計師來說無疑是一份饋贈,也是對開源意識的激勵。如果初略去審視這款字體,有兩個明顯的特徵,一個是字體的框架結構區別於傳統的宋體,更接近黑體,如中宮大、重心低等特徵;另一個特徵就是字體輪廓的曲線特徵,即貝塞爾曲線的繪製結構和策略。思源宋體的輪廓繪製使用了簡潔並求效率的方式,除了特殊的筆畫,基本採用單條曲線(即頭尾兩個節點)完成,就像是“丶”,有着較大走勢變化的形狀,也使用單條曲線繪製完成,這樣帶來的結果是,過度拉長其中一條曲線的控制點手柄,就像“要”字的長點的尾部,思源宋體就靠單條曲線完成大弧度,選擇此種曲線繪製策略應是綜合了對效率的考慮,如果只是從形態角度來考慮,這種繪製方式當然不會是最佳的選擇。 […]
[…] 關於思源宋體的問答 […]
[…] Liu,關於思源宋體的問答, […]
[…] 年 Adobe 公司發布的泛中日韓字體「思源」系列就採用了一個相對激進的做法:第一步先使用 OpenType 中的「字形組合」ccmp 特性(即 Glyph […]