


「孔雀計劃:中文字體排印的思路」系列倡導從中文出發、以中文的思維方式討論中文排版。精妙的中文排版並不僅僅是「標點懸掛」那樣的小技巧,而是一個有設計邏輯的系統。在本篇里,筆者着重討論一個大家容易忽略的中文換行問題。
談到中文排版的換行問題,大家可能首先會想到避頭尾規則。由於避頭尾涉及到標點,筆者會另文敘述。在本篇里,筆者通過兩個實例,聚焦中文排版中標點以外的換行問題,挖掘一下那些容易被忽視的中文排版需求。
按語義換行
首先請看下圖這部漢譯的西文著作。其中文版設計者聲稱:「他(原書作者)一直拒絕那種齊頭齊尾的強制對齊排版,而是一行一行地細心確定每行最末端詞彙。……中文版設計基本復刻了這一傳統。」該書全文放棄了兩端對齊而採用了左對齊,並號稱是依照語義按詞換行。但是這種中文排版真的美觀且易於閱讀嗎?

筆者曾在拙文《「中西之別」重考》里指出過,西文採用「按詞分寫」,詞與詞之間有詞距(word space),因此排版引擎首先選擇在空格處換行。為了得到更好的排版效果,還要考慮連字處理問題(hyphenation)將詞斷開。由於西文字母體量小,可供調整的空間相對零碎,因此左對齊後再調整,可以讓整個頁面右側不齊的行尾形成類似波浪的形狀,非常美觀。這也許就是原書的外國作者所偏好的。
而在東亞,有且僅有一個文種——韓文的排版斷行具有「雙重性」。現代韓文在正詞法(orthography)的層面規定了必須進行「分寫」(띄어쓰기),因此韓文排版可以有兩種風格:既可以像西文那樣按詞換行,也可以中文這樣每個字後都可換行。但與西文不同的是,韓文即便把詞斷開也不需要用連字符 (-) 連接。韓文的換行規則在 W3C《韓文排版需求》里有如下記述(原文為韓英對照,筆者試譯):
當行末為韓字(諺文)時,可以「字」(글자)或者「詞」(어절/語節)為單位斷行。文章作者可以決定按段落或者通篇採用任意一種方法。

眾所周知,長篇文章里西文算「詞」數,而中文是算「字」數。其實中文裡的「單字成詞」的情況很常見,「字」「詞」很難嚴格區分,導致漢語的嚴格分詞反而很困難。中文的書寫體例里也從來不存在「按詞分寫」。唯一的特殊情況是對外漢語教學的教材里,但這也僅限於初級教材,中級之後就和普通的中文出版物一樣不按詞分寫了。對於機器,自然語言處理遇到的的「中文分詞難」已經通過技術解決;而對於人來說,閱讀中文本來就不應該過分突出「詞」的作用——中文讀者不會對此造成困惑,排版也無須多此一舉。對漢語母語者來說,並不會因為按語義換行排版就能極大提高閱讀效率。
漢語經過漫長歷史的不斷演化,詞的音節也在不斷增加,現代漢語的詞彙一大特點就是「以雙音節詞為主」。據統計,《現代漢語詞典》《現代漢語常用詞詞頻詞典》里雙音節詞約佔 60 %。這樣造成的局面是,即便要對中文「按詞換行」,行末遇到不完整的詞,也無非是一兩個漢字的寬度調整。比起西文字母的零碎寬度,中文方塊字顯得碩大,這個寬度如果按照「左齊、右不齊」的排版,只會造成難看單調的鋸齒狀,與西文的大波浪差距甚遠。這一點,其實與之前拙文談「標點懸掛」時提到的西式「視覺對齊」是一個道理。
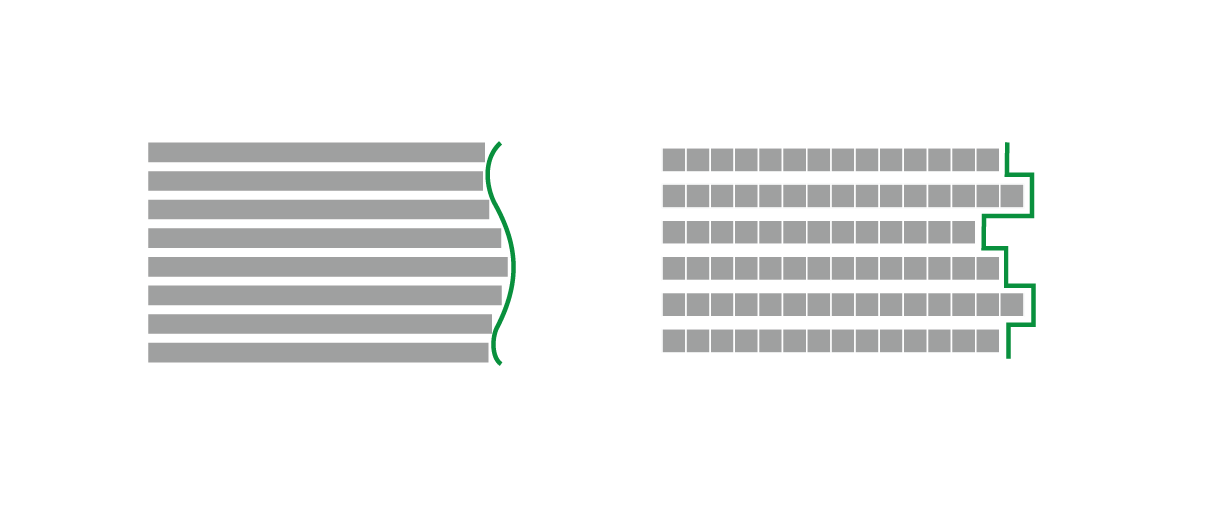
自從近代字體排印發展以來,漢字已經是固定的「方塊字」,排版造型趨「齊」使內部驅動力也偏好「兩端對齊」。而且,如果能將標點擠壓等間距調整到位,其實「左對齊」和「兩端對齊」的差別會變得很小。無論是看中文的語言詞彙特點、還是看漢字造型和排版特性,都沒有必要將長篇的正文做成「按詞斷行」的左對齊,既沒有用也不好看。
需要注意的是,「按詞換行」在標題里是必要的。特別是在報紙新聞等用於「秒讀」媒介的標題里,類似「我外交部強烈譴責伊拉克/大使館被炸事件」這樣的換行的確不妥。標題要求轉行時不能產生歧義,不得割裂詞組,而且對於虛詞也要認真處理,一般出版社會規定「的」這類虛詞不能放在行首,「和」「與」不能放在行末。而正文與標題不同。在正文這樣一個更長更流暢的語流里「按詞換行」的必要性大大降低,而且也會導致龐大的工作量。全文按詞斷行,如果沒有機器語言分析的輔助,就只能靠手工,這樣必然會有缺漏。比如,圖例中倒數第四行的「字寬」一詞就被錯誤地斷開了,設計者自己也沒有徹底實現其設計邏輯。
針對圖例這個案例來說,由於該書是譯作,中文版設計者強調這是依照原書作者的偏好,也許也是為了增加「設計感」。但是,只要譯作是中文,必須符合中文最低限度的基本行文和排版的習慣——希伯來文作品的中文版如果也按照希伯來文從右往左排版,估計絕大多數中文讀者都會不適應。因此,作為設計師必須清楚地理解「最低限度」在哪裡,應該不應該踩到警戒線,哪些是可以嘗試而哪些是違反客觀規律的,這些都要謹慎決策。否則,生搬硬套西文排版的方法而忽略中文本身的內部規律,只會成為東施效顰。
搗亂的數字
那麼,中文排版在換行時不用在意語義,那就只需要考慮標點嗎?下圖就是一份完全沒有標點的排版,來自中國某字體大廠商的一份字體樣張,看看這裡出了什麼問題。

由於內容是佛典,因此設計師採用了「無標點」+「兩端對齊」。對於中文來說,這理應是最簡單的排版模式,如果按部就班,應該會按照稿紙模式的中式網格形成「縱橫對齊」的版面。但令人意外的是,實際效果並非如此:第四行和第五行的字距被拉開,每行只有 18 字;而其他幾行的字距更緊,每行 19 字。筆者通過軟件模擬比對,確認這是使用 Adobe InDesign 中文版的默認設置排出來的效果。為什麼會出現這種情況呢?
原來,問題的關鍵在「千二百五十」這個漢字數字。Adobe InDesign 中文版里有一個被稱作「連數字」的功能,不讓數字在換行時從中斷開。在此例里,該功能「智能」地判斷出了第五行的行末遇到了「千二百五十」這個數字,為了保證其不斷開,只好將整個數字挪到下一行的第六行行首,而第五行多出的空白,則按照「CJK 段落書寫器」的算法,不僅均攤到第五行,還均攤到了第四行內,最後導致第四、第五行這兩行字的字距都發生了變化。

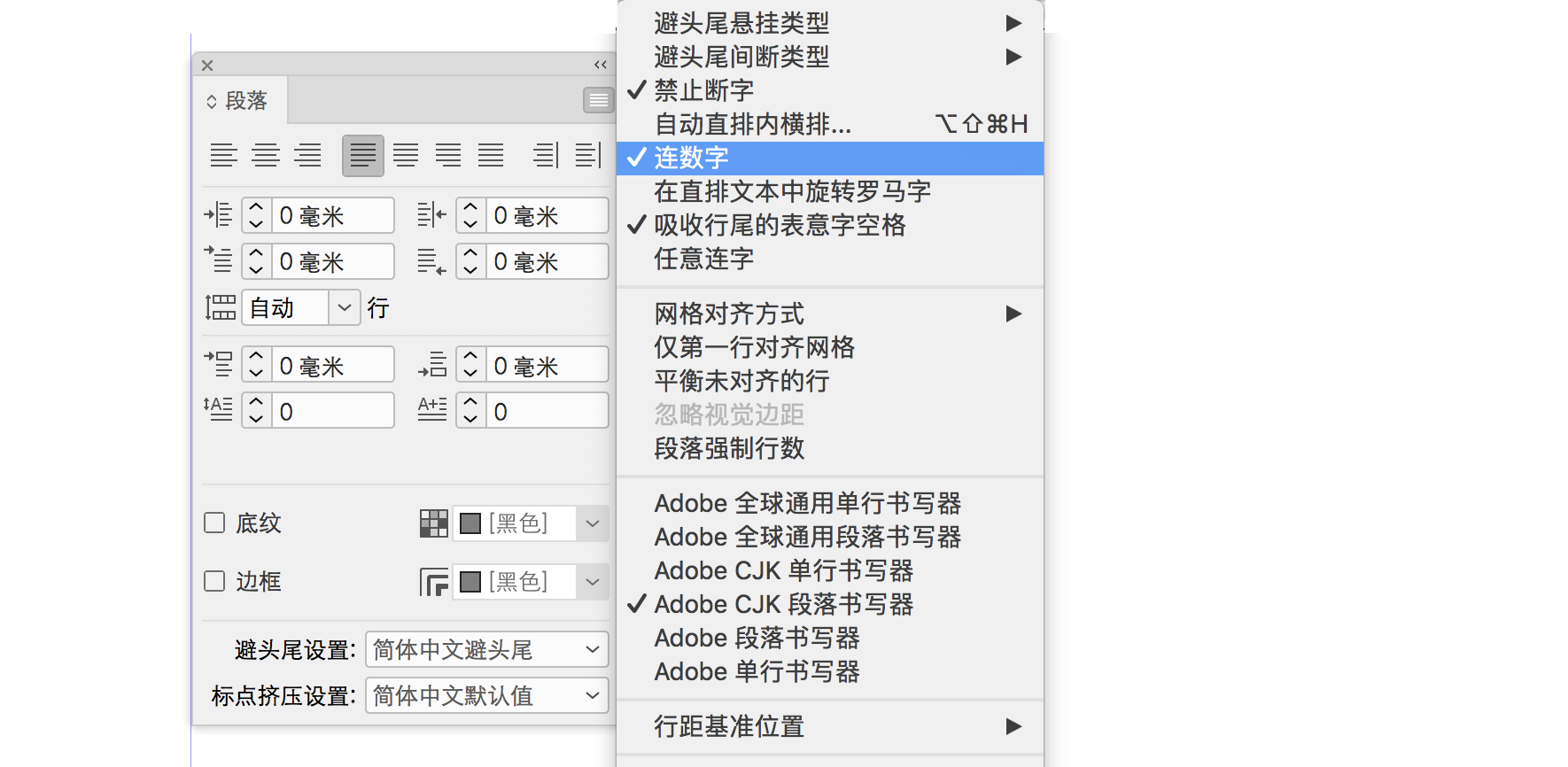
「連數字」這個功能自 InDesign 1.0 版就存在,而英文版並無此功能,可見這是專為中日韓的東亞版開發的,但筆者可以毫不為過地稱之為 Adobe 的一大失誤。
本來「連數字」的功能是讓以0〜9組合而成的所謂「全角阿拉伯數字」,以及漢字數字,包括以「十百千萬億兆」等表數位的漢字組成的數字連起來而不斷開,如遇行尾則推到下一行。然而,用戶卻對 Adobe 的這個「熱心」功能哭笑不得:按照上述邏輯「該有的沒有」,因為這個算法並沒有包括漢字數字〇以及大寫的「壹貳叄」等字符,因此對於「二〇」這樣的數字並不會奏效;而「不該有的卻有」,因為軟件只是單純檢測字符而無法智能判斷語意,遇到類似「以防萬一」中「萬一」這樣的詞也會被誤判成數字進行多餘的處理;而且,夾在漢字數字中間的逗號和間隔號甚至會被當做分節號、小數點處理。

退一萬步來說,阿拉伯數字斷開會導致位數不清,的確是應該禁止斷開,但是漢字數字就沒完全沒有必要了。事實上,中文排版里從來沒有過禁止漢字數字的行尾換行。考慮到 Adobe InDesign 的東亞版完全是依照日本工業標準 JIS 4051:2004 《日本語文書的排版方法》中的需求進行開發的,這個功能可能來自日文排版需求。可是經過調查才發現的事實是,開發者完全曲解了 JIS 4051 的本意。在該規範中,定義如下(原文為日文,筆者試譯):

136) 連數字:一位以上連續的數字。包括分節用的逗號、空格,以及小數點的圓點。備註:作為和字處理的全角數字,以及作為西文處理的帶有固有寬度的數字除外。……139)和字:構成和文(即日文)的漢字、假名、數字、標點以及其他符號。豎排時,還包括全角西文。
雖然沒有明確寫出,但通過上下文可以看出該規範中定義的「連數字」應該與漢字數字無關。之後的 2012 年萬維網聯盟(W3C) 以此規範為基礎而制定的 《日文排版需求》中在對「連數字」的定義里更是明確了不包括漢字數字。因此,InDesign 口口聲聲說的「遵守 JIS 規範」只是一個美麗的誤會。打開 Adobe 官方的 InDesign 用戶指南中文版,其中如此解釋道:
連數字用於防止數字斷開。此外,該選項根據 JIS 規範處理數字字符串中的標點間距(適用於日文)。……要打開連數字,請從 “段落” 面板菜單或 “控制” 面板菜單中選擇 “連數字”。
而通過上述分析,我們可以知道:第一,漢字數字本來就可以斷開換行,「連數字」對漢字也進行處理是多此一舉;第二,這個功能誤解了日本的 JIS 4051 規範,是一個錯誤的實作;第三,用戶指南里聲稱其「適用於日文」,但實際也作用到了中文上;第四,用戶指南讓人誤解為該功能「需要則開啟」,而實際上該功能是默認開啟,用戶反而必須手動關掉。可以說,這段官方說明漏洞百出,不僅沒有說明清楚功能,反而有誤導的嫌疑。
與日文用戶不同,中國大陸用戶極少會實際使用0〜9這些「全角阿拉伯數字」,而普通的所謂「半角數字」在軟件里會同西文一起處理而不會斷開,因此避免阿拉伯數字斷開這個需求完全不需要這個「連數字」的功能,而開啟這個功能則是有百害而無一利。讓情況雪上加霜的是,Adobe 將這樣一個錯誤的實作設置為「默認開啟」,多挖了個陷阱讓用戶往裡跳,而絕大多數用戶則是在不知情的情況下落入陷阱而無法自拔。所以筆者在此強烈建議 InDesign 用戶修改默認設置,將「連數字」功能關閉,減少意外而不必要的字距調整導致版面失調。
?小技巧 Adobe InDesign 里有「應用程序默認」和「文檔默認」兩種默認狀態。啟動 InDesign 而不打開任何文檔,修改設置即是針對整個軟件的「應用程序默認」,會影響到之後所有的新建文檔。與此相對,如果在打開文檔的狀態下修改設置,則僅是針對改文檔的「文檔默認」,而對之後新建的文檔沒有作用。因此,用戶只需要在啟動 InDesign 而不打開任何文檔的狀態下,到「段落」面板的選項菜單里關閉「連數字」選項,即可在今後免除該功能自動啟用的困擾。
當然,本例的排版還涉及到了「段落書寫器」和「單行書寫器」的問題。儘管 Adobe 聲稱「段落書寫器」是更好的算法並將其設為首選項,但依照筆者排版經驗還是「單行書寫器」更靠譜,因為這樣不會將一行的錯誤字距殃及到其他行。如果本例能使用「單行書寫器」,只會影響第五行的排版;而由於默認使用的是「段落書寫器」,導致連累到了毫不相關的上一行,整個段落的字距從第四行就開始亂掉。關於書寫器的算法邏輯和用法推薦,本系列將另文闡述,在此就不做過多展開了。

特殊情況特殊處理
如前所述,中文排版的換行不必太在意語義上的「按詞換行」,漢字數字也可以換行斷開,但這並不是說沒有特殊情況。事實上,在實際的媒體工作中,中國有很多報社都需要「專用詞管理」,定義一些需要「特殊關照」的詞彙並進行維護,確保它們在換行時不會被斷開。這些所謂的「專用詞」,基本上是重要的專有名詞,可以是人名,也可以是國名、地名,而具體的定義則沒有固定標準,依照報社、出版社的特例風格和規定而有所不同。
其實,對專有名詞進行換行管理的傳統,在西文排版里也有慣例。英國英語的權威體例《牛津風格手冊》里就指出(原文為英文,筆者試譯):
即使不需要連字符,在換行時也應該遵守一些限制:而在美國,沿用美聯社體例風格的《休斯頓大學寫作體例》在「連字符」一節里也提到:
……
如果可能,不要將地名、(特別是)人名斷開。如果無法避免,人名應該從姓和名之間斷開,或者從首字母(至少必須要兩個)和姓之間斷開。不能將姓名與其修飾成分斷開。
應避免將人名、專有名詞、電話及傳真號碼,以及電子郵件、網頁、街道和郵寄地址斷開。
歐美出版社特別注意避免將人名換行,不僅體現了對他人的尊重,更重要的一個功能是可以避免加上連字符 (-) 的姓氏被誤認為「複姓」,因為在西方國家中出於婚姻、貴族世襲等各種原因而使用複姓的情況比較常見。而在中文世界,雖然「抬格」式的排版已被廢止,但細緻的排版依然也會沿襲「人名不斷行」的傳統。當然,這樣的決策肯定會加大排版的複雜度,因此在實際工作中往往只選擇一些重要、特殊的專有名詞進行處理,而其他專有名詞就忽略掉,這就是出版社「專用詞」習慣的來源。翻開上世紀七十年代出版的《活字排版工藝》里,我們可以讀到:
揀正的毛坯需要注意一下幾點
……
(3)有關政治性的詞句、領袖姓名、國名等,要特別注意,不能揀錯,每揀一組詞句時,需要認真默讀一遍。領袖名字趕到行末時不要分拆回行,應在上行用襯線加大字行,將領袖名字整個移在下行的行首。

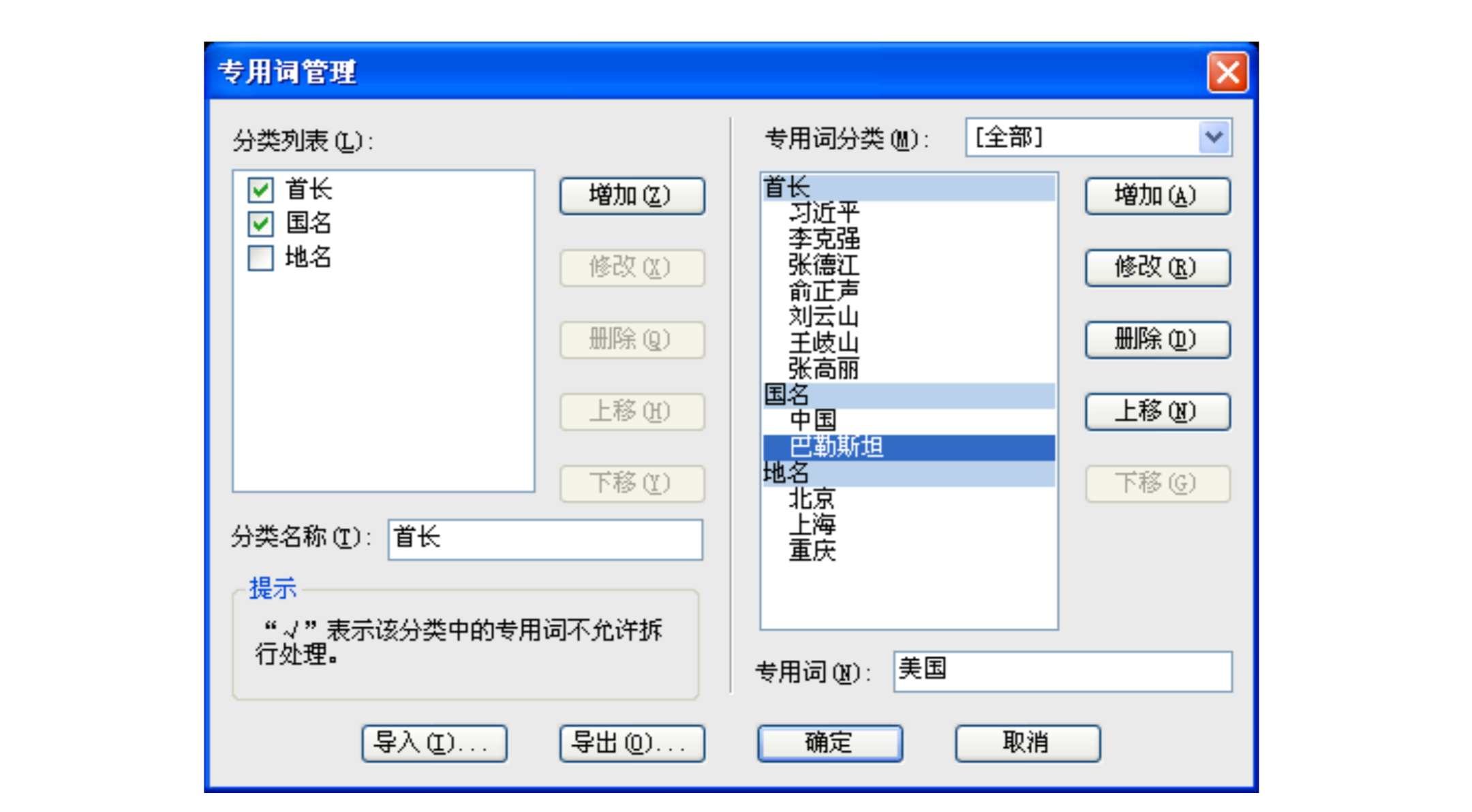
從電子出版的角度來看,通過軟件實現這個功能並不困難。但是一些國外廠商的軟件,比如 Adobe InDesign 里,無論是文本「不換行」功能,還是結合正則表達式 (GREP) 都需要手動逐個定義所需詞彙,而且提高了使用門檻。相對地,土生土長的中國軟件——方正飛騰就提供了「專用詞管理」功能,在一個界面里就可以很輕鬆、靈活地實現管理功能,方正公司甚至還為此於 2015 年提交過「專用詞不拆行處理方法和裝置」的專利申請1。因此方正產品曾佔國內出版市場九成市場份額是有其原因的。
誠然,正如本系列文章里多次提到的,正文排版其實是一個妥協的過程。定義越多禁止換行的「專用詞」,就會有越多的位置、字距需要調整,就越容易偏離中式網格的秩序。因此這沒有簡單的對錯,要根據具體的體例格式,對優先順序和程度進行決策。
網絡時代
如今的網頁和電子書設計中,我們還是推薦盡量遵守 CSS 標準。但是由於各個文種的情況非常複雜,W3C 在《CSS 文本模塊》(第三級、工作草案版)截止至本文執筆時依然都沒有形成最終稿。其中在第五章「斷行和詞界」中提到(原文為英文,筆者試譯):
在其他一些書寫系統(如中文、日文、彝文,以及部分韓文)中,軟包圍機會2應依照音節界,而非詞界。在這些系統里,除去某些字符組合以外,行可以在任意處斷開。而且,根據排版體例,這些限制的嚴格程度會有所不同。CSS 不會完整定義所有的軟包圍機會,但是會提供一些控制以區別常見的不同做法。
這同樣從側面說明,一般情況下中文沒有必要按詞斷行,包括漢字數字。另外,由於 CSS 的 white-space 屬性也能控制換行、空白、tab 等的動作,因此如果需要保證不換行,可以將這個屬性賦值 nowrap 處理。
以上是從排版層面的考量。如果一定要對特殊詞彙不換行進行控制,可以從字符的層面使用 Unicode 的控制字符 U+2060(WORD JOINER,簡稱 WJ,詞連接符)保證特殊詞內部不斷開,相對來說比其他方法更能保證在不同的環境下的效果。Unicode 自 3.2 版就引入了這個控制字符,其在 HTML 的轉義表達為 ⁠。這個字符在顯現時不會佔用字寬,讀者完全看不見這個字符,不會為排版造成負面影響,但能明確提示用戶代理(比如瀏覽器)禁止在該位置換行。
需要注意的是,Unicode 定義了相當數量的控制字符,用戶最好能夠按照規定正確使用,比如中文的「特殊詞彙不換行」功能里就不推薦使用 U+200D(ZERO WIDTH JOINER,零寬連接符),因為這個字符原本是為阿拉伯文、天城文等書寫系統里單詞內字母連寫用的。
小結
中文排版中除標點以外的換行位置,一直被認為是任意而不需要控制的。而實際上卻有一些人為因素、軟件因素會添加多餘的換行判定,這是應該避免的;在「不控制」的一般條件下,對特殊情況進行管理即可。
作為「中文排版需求」來說,對於換行機會並沒有做出更多的解釋,筆者認為應該為各種實作提供一些信息,至少要保證以下幾點:
- 標點換行:標點避頭尾以及禁止分割,這是最重要的部分,會另做討論;
- 阿拉伯數字:阿拉伯數字的內部,以及小數點處禁止斷成兩行;
- 特殊數值單位:百分號、千分號、攝氏度等符號應該禁止與前面的數值斷成兩行;
- 上下標、注釋記號:一些單位及各種學科里出現的上下標(如 m2 中的 2 )與前面的字符,以及 ㈠ ㊁ Ⅲ ④ 等腳註、尾注符號與被注釋的詞之間不應斷成兩行;
- 混排的外文:混排在中文裡的外文,應該按照外文習慣,如英文按照英式斷詞連字(hyphenation)、藏文需要按照藏文的詞界進行斷行。 對於較長的網址、郵件地址,實際屬於西文的字符串,應該實際情況靈活處理,建議在 @ 等符號處斷開,不能隨意添加連字符;即使斷開,行首也不能隨意修改大小寫。

上述幾個需求里,阿拉伯數字和外文的控制,實現方式已經相對成熟,而真正「純正」的中文排版問題應該放在標點和注釋記號上。其實,本文的注釋用的上標數字 1、2 與前面的漢字之間就已經插入了「詞連接符」,避免注釋用的上標數字和其注釋詞被斷成兩行。有興趣的朋友可以嘗試改變窗口寬度來測試一下實際效果。
在前述基礎原則之上,各個出版社、內容創作機構可以指定內部的書寫體例。比如對於漢字數字,有些比較寬鬆的做法不加控制,因為多位數一般採用阿拉伯數字;而另一些稍微嚴格的體例則會認為,表示數量、有明確位數的數字,如「三百六十五」斷開不會有歧義,但是如果記成「三六五」而又斷開則會發生「數量」與「編號」的歧義而應該加以控制。這個問題的實質是「數字用法」的規範問題,因此筆者建議應該先在編輯時在「用字法」層面先做出相關表記規定,再進行排版的風格規定,否則很難兩邊同時權衡。至於特殊詞彙管理,不屬於一般排版規則,各個機構內部自行決定、執行就好。過長的網址、郵件地址是最近才出現的新問題,提倡靈活處理而不應該做過多死板限制。總之,搞清楚「有所為有所不為」是制定排版邏輯的基礎,在字體排印的相關策略制定時,一定要切記過猶不及。
註:
- 中華人民共和國發明專利申請《專用詞不拆行處理方法和裝置》,申請公布號 CN 104572750 A,申請發布日 2015 年 4 月 29 日,申請人:北大方正集團有限公司,發明人:楊燕菲、梅林、楊雷鳴。↩︎
- 軟包圍機會(soft wrap opportunity):網頁盒子容器對內容進行包圍時允許斷開的點。↩︎
- R. M. Ritter, The Oxford Style Manual, 2003, Oxford University Press.
- 曹洪奎,《活字排版工藝》,1979,輕工業出版社
- 劉源,《現代漢語常用詞詞頻詞典》(音序部分),1990,宇航出版社。
{kind=link}
6 個相關討論
軟包圍機會,翻譯得好彆扭
to 讀者:
覺得彆扭更多是因為這是術語,讀不習慣,而並不是翻譯本身的問題。比如這個詞的「軟」和「軟回車」「硬回車」的意思一樣,再說網頁設計里「盒子模型」這類詞的都是一般人覺得怪怪。作為術語,只要內行人都知道是什麼,而且沒有歧義就夠了。
西文段尾形成的 “大波浪” 其實並不是好的取向,反而如果形成了太明顯的形狀還要避免。Jost Hochuli 就提到,段尾要優先做到 “長短長” 的切換,而且這種切換還要帶有優雅的韻律和節奏感……這也可以理解,為什麼 Hochuli 在排段落的難度比較裡面,把 “帶有折行的齊頭散尾” 排在第一難。
請問“Unicode 的控制字符 U+2060”這個字符在InDesign里怎麼輸入?
To Zhang Qingtian: 在 InDesign 里如果要手動指定某個單詞不斷開,方法請見 Adobe 官方幫助文件。經測試對西文、中文均有效。
本文不打算寫成 InDesign 教程,請善用 Adobe 官方資源。
今天看到「美國駐華大使館和領事館」網站上的斷行設計就想起了這篇文章了。
六句句子里有四句斷行在不該斷的地方: https://i.imgur.com/L38jDwB.png
我還以為是瀏覽器渲染的問題,一看源代碼竟然是手動插入的 br 換行符: https://i.imgur.com/o4Bzyih.png
5 個Trackbacks
[…] 行行當機不立斷 […]
[…] 其實,這些符號從實際排版效果來考慮應該是「避中間」,也就是說這些符號與其修飾內容也應該組合成「不可分字段」而不能中間斷開。這些斷行位置判斷的一些特殊情況,筆者已在《行行當機不立斷》一文分析過,不再贅述。 […]
[…] 在〈行行當機不立斷〉一文中提到了 InDesign「連數字」功能帶來的排版問題,刊於 Type is […]
[…] 這個「禁止斷字」是 Adobe 為東亞排版而設置的功能,或者應該嚴格地說,這是為了實現日本 JIS X 4051「分離禁止」處理而設置的功能。翻閱 JIS X 4051 原文可以知道,日文排版所謂「分離禁止」是指字符之間不能斷開,且在標點擠壓等間距調整處理時也不被拉開;具體對象有破折號、省略號、「連數字」、西文單詞等。顯然,與「不換行」單純功能相比,這個需求更突出了「在標點擠壓等各種間距調整處理時也不被拉開」的重要性。如果忘記定義,破折號的兩個字符之間在兩端對齊調整字距時依舊有被斷開的危險。因此,即使決定要採用「寬式」風格不避頭尾,在「避頭尾規則集」對話框上方里的「禁止在行首的字符」里刪除掉相關字符,但依然要記着把所有這些相關字符(為了保險,建議把 U+2014、U+2015、U+2500 等等)都寫入底部「禁止分開的字符」定義表裡,保證「避中間」,不至於連用時從中間斷開。 […]
[…] 本站編輯錢爭予早在 2013 年就曾撰文《縱橫對齊不是現代方法》。作為現代漢語的表記形式,既然現代中文已經不能沒有標點符號,那麼現代中文排版必須對其進行認真細緻地調整,根據易讀性進行細緻的標點寬度調整、避頭尾處理及換行位置處理,以優先保證易讀性。對於混排的阿拉伯數字和西文,也要在現行編輯層面的正字法檢查的基礎之上(比如權衡使用阿拉伯數字和漢字數字,比如夾雜的西文改用中文詞彙等),再進行形式的選擇(比如在豎排時合理地採用所謂「全角字符」)。不應該一味讓內容妥協於形式,單純表現形式美的「縱橫對齊」,這樣的效果這也絕對不是合理使用網格系統的必然結果。 […]